Hadoop
数据单位排序
bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB
1、组件
- MapReduce 计算
- Yarn 资源调度
- HDFS 数据存储
- Common 辅助工具
2、HDFS 分布式文件系统
Hadoop Distributed File System
- NameNode(nn) 存储文件的元数据,如文件名,文件目录结构,文件属性,以及每个文件的块列表和块所在的DataNode等
- DataNode(dn) 在本地文件系统存储文件块数据,以及块数据的校验和
- Secondary NameNode(2nn) 每隔一段时间对NameNode元数据备份
3、YARN 资源协调者
Yet Another Resouce Negotitator
- RM (ResourceManager) 整个集群资源(内存、CPU) 的老大
- NM (NodeManager) 单节点服务器资源老大
- AM ApplicationMaster 单个任务的老大
- Container 容器,相当于一台独立的服务器,类里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络
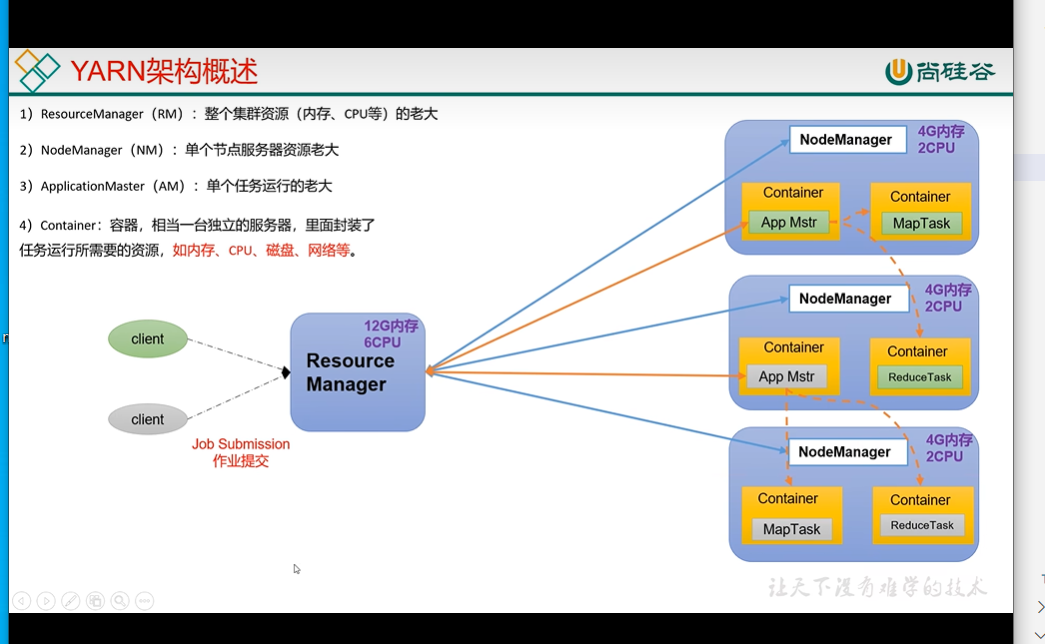
- 客户端可以有多个
- 集群上可以运行多个ApplicationMaster
- 每个NodeManager 上可以有多个Container
MapReduce
将结算过程分为两个阶段 Map 和 Reduce Map:并行处理输入数据 Reduce:对Map结果进行汇总
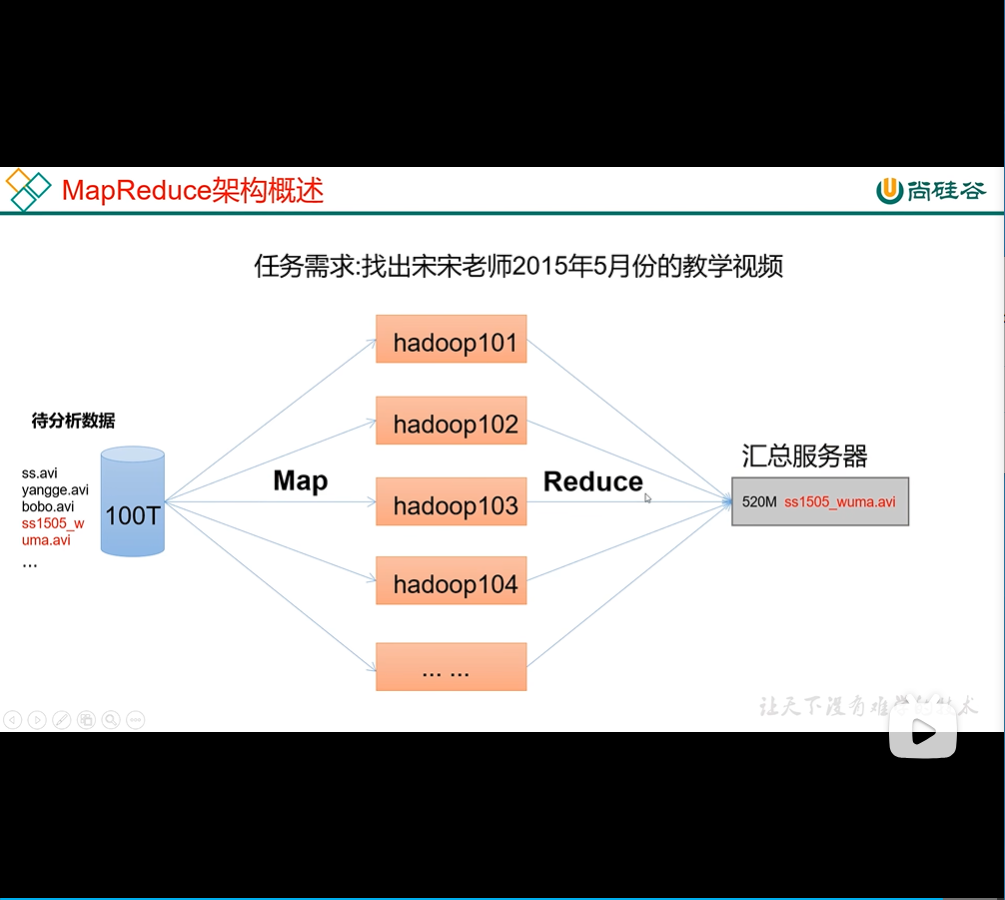
4、三者之间的关系
HDFS 存储 YARN 去拿存储 MapReduce 协调调配上面两种过程 
5、大数据技术生态
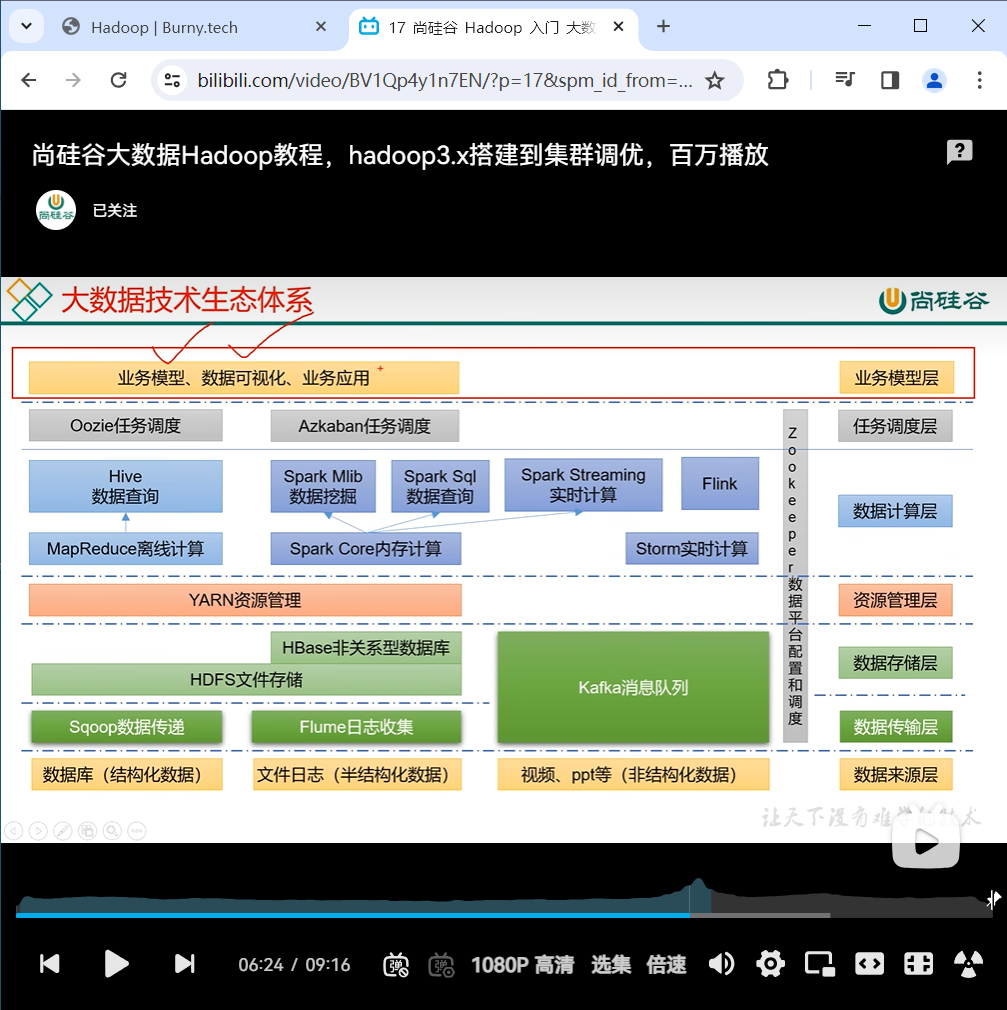
1)Sqoop:Sqoop 是一款开源的工具,主要用于在 Hadoop、Hive 与传统的数据库(MySQL) 间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进 到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中。 2)Flume:Flume 是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统, Flume 支持在日志系统中定制各类数据发送方,用于收集数据; 3)Kafka:Kafka 是一种高吞吐量的分布式发布订阅消息系统; 4)Spark:Spark 是当前最流行的开源大数据内存计算框架。可以基于 Hadoop 上存储的大数 据进行计算。 5)Flink:Flink 是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。 6)Oozie:Oozie 是一个管理 Hadoop 作业(job)的工作流程调度管理系统。 7)Hbase:HBase 是一个分布式的、面向列的开源数据库。HBase 不同于一般的关系数据库, 它是一个适合于非结构化数据存储的数据库。 8)Hive:Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张 数据库表,并提供简单的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce 任务进行运 行。其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 统计,不必开 发专门的 MapReduce 应用,十分适合数据仓库的统计分析。 9)ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、 名字服务、分布式同步、组服务等。
6、安装
yum install -y epel-release net-tools vim
systemctl stop firewalld
systemctl disable firewalld
# 删除jdk
rpm -qa |grep -i java | xargs -nl rpm -e --nodeps
rpm -qa 查询所有的rpm安装包
grep -i 忽略大小写
xargs -nl 表示每次只传递一个参数
rpm -e -nodeps 强制卸载软件
Extra Packages for Enterprise Linux 是为“红帽系”的操作系统提供额外的软件包, 适用于 RHEL、CentOS 和 Scientific Linux。相当于是一个软件仓库,大多数 rpm 包在官方 repository 中是找不到的
6.1、安装jdk 和 安装hadoop
在centos71 上操作
下载 https://archive.apache.org/dist/hadoop/common/
tar -zxvf jdk.tar.gz 1.8版本
tar hadoop.tar.gz 3.1.3版本
/etc/profile.d
export JAVA_HOME=/data/soft/java/jdk8
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/data/soft/hadoop/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
### 复制到其他服务器 适合第一次
# 从当前机器 /data 整个文件夹 复制到 72 /下面
scp -r /data/ root@192.168.1.72:/
scp -r /data/ root@192.168.1.73:/
scp -r /data/ root@192.168.1.73:/
## 从71机器 /data 整个文件夹 复制到 当前文件夹 / 下面
scp -r root@192.168.1.71:/data /
### 同步命令--区别于完全复制 如果文件没改变的话是不会传输的 适合第二次同步等等
-a 归档拷贝 -v 显示过程
rsync -av /data root@192.168.1.72:/
xsync
### 期望脚本在任何路径都能使用
# 查看有哪些目录下是环境变量
[root@centos71 ~]# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/data/soft/java/jdk8/bin:/root/bin:/data/soft/java/jdk8/bin:/data/soft/hadoop/hadoop/bin:/data/soft/hadoop/hadoop/sbin
mkdir -p /home/burny/ba
touch /home/burny/ba/xsync.sh
# xsync
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in centos71 centos72 centos73 centos74
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
## ssh 公钥私钥登录
### 192.168.1.71 登录 其他服务器
在四台服务器都执行以下语句
ssh-keygen -t rsa
ssh-copy-id 192.168.1.71
ssh-copy-id 192.168.1.72
ssh-copy-id 192.168.1.73
ssh-copy-id 192.168.1.74
## 四台服务器都是同样的hosts
[root@centos72 etc]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.71 centos71
192.168.1.72 centos72
192.168.1.73 centos73
192.168.1.74 centos74
xsync /home/burny/ba/xsync.sh
6.2、重点目录
bin目录下 重点命令
hdfs
mapred
yarn
etc 重点配置
hdfs-site.xml
core-site.xml
yarn-site.xml
mapred-site.xml
workers
sbin目录下
start-dfs.sh
start-yan.sh
mr-jobhistory-daemon.sh
hadoop-daemon.sh 单节点启动我
share目录下
doc 说明文档
6.3、运行模式包括
单机模式:单机运行 数据存储在linux本地
伪分布式模式 也是单机运行,但是具备hadoop集群的所有功能 数据存储在HDFS
完全分布式 数据存储在HDFS/多台服务器工作
6.4、部署规划
NameNode 和SecondaryNameNode 不要在同一台服务器
ReouceManager 也很消耗内存,不要和 NameNode 和SecondaryNameNode 同一台服务器
centos72 centos73 centos74 HDFS NameNode
DataNodeDataNode
和
SecondaryNameNodeDataNode YARN NodeManager ResourceManager NodeManager NodeManager
6.5、配置文件说明
- 默认配置文件
- 自定义配置文件 只有用户想修改某一默认配置时,才需要修改自定义配置文件,更改相应的值
默认配置文件
| 要获取的默认文件 | 文件存放Hadoop的jar包中的位置 |
|---|---|
| [core-default.xml] | hadoop-common-3.1.3.jar/core-default.xml |
| [hdfs-default.xml] | hadoop-hdfs-3.1.3.jar/hdfs-default.xml |
| [yarn-default.xml] | hadoop-yarn-common-3.1.3.jar/yarn-default.xml |
| [mapred-default.xml] | hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml |
6.6自定义配置文件
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml
存放在 hadoop安装目录下 /etc/hadoop
修改配置
在centos72 上操作 1、core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://centos72:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/soft/hadoop/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>burny</value>
</property>
</configuration>
2、hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>centos72:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>centos74:9868</value>
</property>
</configuration>
3 yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 3.2 以上不需要 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value>
</property>
</configuration>
4、MapReduce-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5、 将以上配置文件分发到 centos72 centos73 centos74
pwd
/data/soft/hadoop/hadoop/etc
xsync hadoop/

7.群起集群
7.1、配置workers
在centos72 上操作
vim /data/soft/hadoop/hadoop/etc/hadoop/workers
centos72
centos73
centos74
注意:该文件中添加的呢容结尾不允许有空格,文件中不允许有空行
同步所有节点的配置文件
xsync.sh /data/soft/hadoop/hadoop/etc/hadoop/workers
7.2、启动集群
1、如果是第一次启动,需要在centos72 节点格式化NameNode
注意:格式化NameNode 会产生新的集群ID,导致NameNode 和DataNode 的集群id不一致,集群找不到以往的数据。如果集群在运行中报错,需要重新格式化NameNode的化 ,一定要先停止nameNode 和dataNode 进程,并且要删除所有机器的data 和logs 目录,然后再进行格式化。
在centos72执行
hdfs namenode -format
打印出来:
************************************************************/
2024-04-09 15:50:35,806 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
2024-04-09 15:50:36,054 INFO namenode.NameNode: createNameNode [-format]
Formatting using clusterid: CID-451e9f18-74e3-4289-9098-6f00ec1a81bf
2024-04-09 15:50:37,428 INFO namenode.FSEditLog: Edit logging is async:true
2024-04-09 15:50:37,453 INFO namenode.FSNamesystem: KeyProvider: null
2024-04-09 15:50:37,457 INFO namenode.FSNamesystem: fsLock is fair: true
2024-04-09 15:50:37,458 INFO namenode.FSNamesystem: Detailed lock hold time metrics enabled: false
2024-04-09 15:50:37,468 INFO namenode.FSNamesystem: fsOwner = root (auth:SIMPLE)
2024-04-09 15:50:37,468 INFO namenode.FSNamesystem: supergroup = supergroup
2024-04-09 15:50:37,468 INFO namenode.FSNamesystem: isPermissionEnabled = true
2024-04-09 15:50:37,468 INFO namenode.FSNamesystem: HA Enabled: false
2024-04-09 15:50:37,581 INFO common.Util: dfs.datanode.fileio.profiling.sampling.percentage set to 0. Disabling file IO profiling
2024-04-09 15:50:37,613 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit: configured=1000, counted=60, effected=1000
2024-04-09 15:50:37,613 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true
2024-04-09 15:50:37,626 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000
2024-04-09 15:50:37,626 INFO blockmanagement.BlockManager: The block deletion will start around 2024 Apr 09 15:50:37
2024-04-09 15:50:37,630 INFO util.GSet: Computing capacity for map BlocksMap
2024-04-09 15:50:37,630 INFO util.GSet: VM type = 64-bit
2024-04-09 15:50:37,634 INFO util.GSet: 2.0% max memory 843 MB = 16.9 MB
2024-04-09 15:50:37,634 INFO util.GSet: capacity = 2^21 = 2097152 entries
2024-04-09 15:50:37,648 INFO blockmanagement.BlockManager: dfs.block.access.token.enable = false
2024-04-09 15:50:37,667 INFO Configuration.deprecation: No unit for dfs.namenode.safemode.extension(30000) assuming MILLISECONDS
2024-04-09 15:50:37,668 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
2024-04-09 15:50:37,668 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.min.datanodes = 0
2024-04-09 15:50:37,668 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.extension = 30000
2024-04-09 15:50:37,678 INFO blockmanagement.BlockManager: defaultReplication = 3
2024-04-09 15:50:37,678 INFO blockmanagement.BlockManager: maxReplication = 512
2024-04-09 15:50:37,679 INFO blockmanagement.BlockManager: minReplication = 1
2024-04-09 15:50:37,679 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
2024-04-09 15:50:37,679 INFO blockmanagement.BlockManager: redundancyRecheckInterval = 3000ms
2024-04-09 15:50:37,679 INFO blockmanagement.BlockManager: encryptDataTransfer = false
2024-04-09 15:50:37,679 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000
2024-04-09 15:50:37,718 INFO namenode.FSDirectory: GLOBAL serial map: bits=24 maxEntries=16777215
2024-04-09 15:50:37,794 INFO util.GSet: Computing capacity for map INodeMap
2024-04-09 15:50:37,795 INFO util.GSet: VM type = 64-bit
2024-04-09 15:50:37,795 INFO util.GSet: 1.0% max memory 843 MB = 8.4 MB
2024-04-09 15:50:37,795 INFO util.GSet: capacity = 2^20 = 1048576 entries
2024-04-09 15:50:37,796 INFO namenode.FSDirectory: ACLs enabled? false
2024-04-09 15:50:37,796 INFO namenode.FSDirectory: POSIX ACL inheritance enabled? true
2024-04-09 15:50:37,796 INFO namenode.FSDirectory: XAttrs enabled? true
2024-04-09 15:50:37,797 INFO namenode.NameNode: Caching file names occurring more than 10 times
2024-04-09 15:50:37,804 INFO snapshot.SnapshotManager: Loaded config captureOpenFiles: false, skipCaptureAccessTimeOnlyChange: false, snapshotDiffAllowSnapRootDescendant: true, maxSnapshotLimit: 65536
2024-04-09 15:50:37,809 INFO snapshot.SnapshotManager: SkipList is disabled
2024-04-09 15:50:37,815 INFO util.GSet: Computing capacity for map cachedBlocks
2024-04-09 15:50:37,815 INFO util.GSet: VM type = 64-bit
2024-04-09 15:50:37,815 INFO util.GSet: 0.25% max memory 843 MB = 2.1 MB
2024-04-09 15:50:37,815 INFO util.GSet: capacity = 2^18 = 262144 entries
2024-04-09 15:50:37,827 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10
2024-04-09 15:50:37,827 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10
2024-04-09 15:50:37,827 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25
2024-04-09 15:50:37,847 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
2024-04-09 15:50:37,847 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
2024-04-09 15:50:37,849 INFO util.GSet: Computing capacity for map NameNodeRetryCache
2024-04-09 15:50:37,849 INFO util.GSet: VM type = 64-bit
2024-04-09 15:50:37,850 INFO util.GSet: 0.029999999329447746% max memory 843 MB = 259.0 KB
2024-04-09 15:50:37,850 INFO util.GSet: capacity = 2^15 = 32768 entries
2024-04-09 15:50:37,914 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1369381148-192.168.1.72-1712677837895
2024-04-09 15:50:37,937 INFO common.Storage: Storage directory /data/soft/hadoop/data/dfs/name has been successfully formatted.
2024-04-09 15:50:38,025 INFO namenode.FSImageFormatProtobuf: Saving image file /data/soft/hadoop/data/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
2024-04-09 15:50:38,300 INFO namenode.FSImageFormatProtobuf: Image file /data/soft/hadoop/data/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 391 bytes saved in 0 seconds .
2024-04-09 15:50:38,327 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2024-04-09 15:50:38,337 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid = 0 when meet shutdown.
2024-04-09 15:50:38,339 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at centos72/192.168.1.72
************************************************************/
# 执行完成之后 根据core-site.xml 中配置的data目录生成/data文件夹
/data/soft/hadoop/hadoop/data/dfs/name/current
VERSION 如下:
#Wed Apr 10 12:43:52 UTC 2024
namespaceID=1195550131 # 当前服务器的版本号
clusterID=CID-47ae3def-0825-4362-88dc-0ae1b8e2bbd7 #集群ID
cTime=1712753032121
storageType=NAME_NODE
blockpoolID=BP-783218066-192.168.1.71-1712753032121
layoutVersion=-64
2、 在centos72 上执行 启动集群
sbin/start-dfs.sh
启动的时候会报错
解决方法
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no defined. Aborting operation.
在start-dfs.sh,stop-dfs.sh 头部添加
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
在start-yarn.sh,stop-yarn.sh两个文件顶部添加以下参数
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
修改完成后,将修改的配置文件copy到其他的节点
[root@centos72 sbin]# start-dfs.sh
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.
Starting namenodes on [centos72]
Last login: Wed Apr 10 12:36:33 UTC 2024 from 192.168.1.4 on pts/0
centos72: Warning: Permanently added 'centos72' (ECDSA) to the list of known hosts.
Starting datanodes
Last login: Wed Apr 10 12:58:50 UTC 2024 on pts/0
centos73: Warning: Permanently added 'centos73' (ECDSA) to the list of known hosts.
centos74: Warning: Permanently added 'centos74' (ECDSA) to the list of known hosts.
centos73: WARNING: /data/soft/hadoop/hadoop/logs does not exist. Creating.
centos74: WARNING: /data/soft/hadoop/hadoop/logs does not exist. Creating.
Starting secondary namenodes [centos74]
Last login: Wed Apr 10 12:58:53 UTC 2024 on pts/0
3、在各自的机器上执行jps 查看对应的节点是否启动
| | centos72 | centos73 | centos74 |
| ---- | ----------------------- | ----------------------------------------- | ----------- |
| HDFS | NameNode <br> DataNode | DataNode <br> 和 <br> SecondaryNameNode | DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
4. 在自己的电脑上加上hosts
192.168.1.71 centos71
192.168.1.72 centos72
192.168.1.73 centos73
192.168.1.74 centos74
5. 查看已经安装的dfs
http://centos72:9870/explorer.html#/
6.在配置了ResouceManager的节点上cetnos73 启动yarn
sbin/start-yarn.sh
[root@centos73 sbin]# jps
3001 DataNode
3226 ResourceManager
3694 Jps
3359 NodeManager
查看yarn 对外暴露的页面
http://centos73:8088/cluster
页面有 No data available in table 因为还没执行
7.4 集群基本测试
7.5 上传文件到集群
在centos72 上执行
hadoop fs -mkdir /wcinput
发现在页面上多了一个路径
http://centos72:9870/explorer.html#/
# README.txt 上传到 /wcinput
/data/soft/hadoop/hadoop
hadoop fs -put README.txt /wcinput
# 上传 hadoop 的tar 二进制文件到dfs
hadoop fs -put /data/soft/hadoop/hadoop-3.1.3.tar.gz /wcinput
# 文件存储在这
/data/soft/hadoop/data/dfs/data/current/BP-1369381148-192.168.1.72-1712677837895/current/finalized/subdir0/subdir0
# 可以看到
-rw-r--r--. 1 root root 1366 Apr 10 13:25 blk_1073741825
-rw-r--r--. 1 root root 19 Apr 10 13:25 blk_1073741825_1001.meta
-rw-r--r--. 1 root root 134217728 Apr 10 13:29 blk_1073741826
-rw-r--r--. 1 root root 1048583 Apr 10 13:29 blk_1073741826_1002.meta
-rw-r--r--. 1 root root 134217728 Apr 10 13:29 blk_1073741827
-rw-r--r--. 1 root root 1048583 Apr 10 13:29 blk_1073741827_1003.meta
-rw-r--r--. 1 root root 69640404 Apr 10 13:29 blk_1073741828
-rw-r--r--. 1 root root 544075 Apr 10 13:29 blk_1073741828_1004.meta
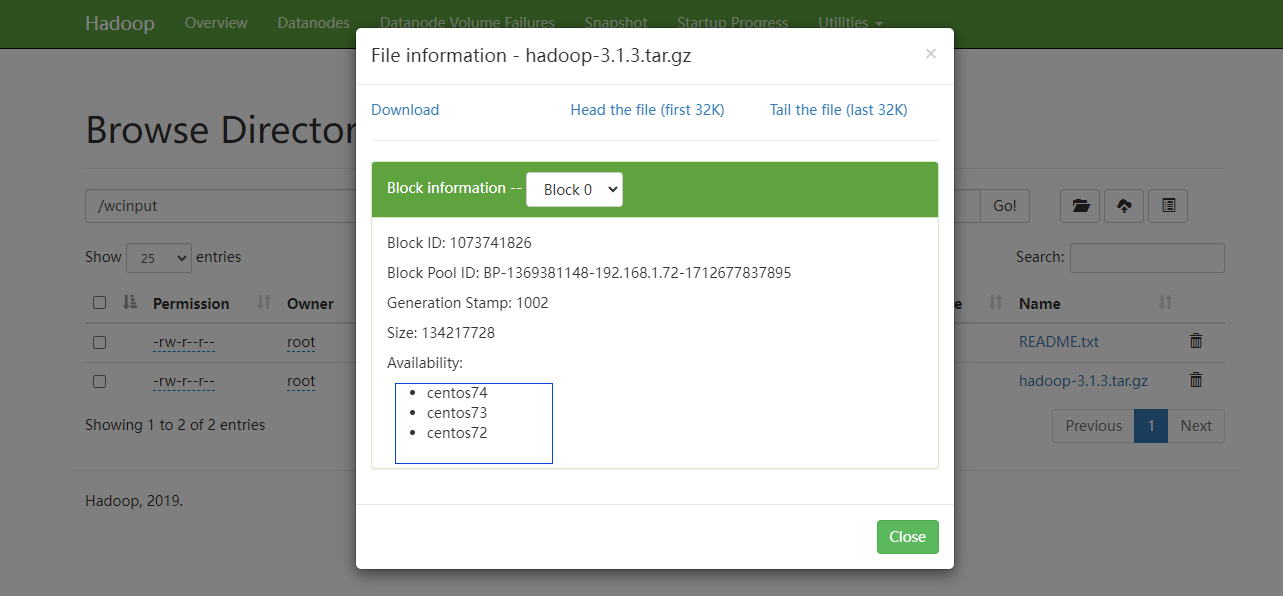
文件被分成了多个文件
blk_1073741825
等开始
由于第一个是字符并且比较小,可以直接cat blk_1073741825
还看到有三个文件 猜测是刚刚上传的 hadoop-3.1.3.tar.gz
用此命令追加到tar.gz
cat blk_1073741826 >> tmp.tar.gz
cat blk_1073741827 >> tmp.tar.gz
cat blk_1073741828 >> tmp.tar.gz
然后解压可以发现是原来的 hadoop-3.1.3.tar.gz
tar -zxvf tmp.tar.gz
``sh
具有高可用,在每个datanode都存储了一份
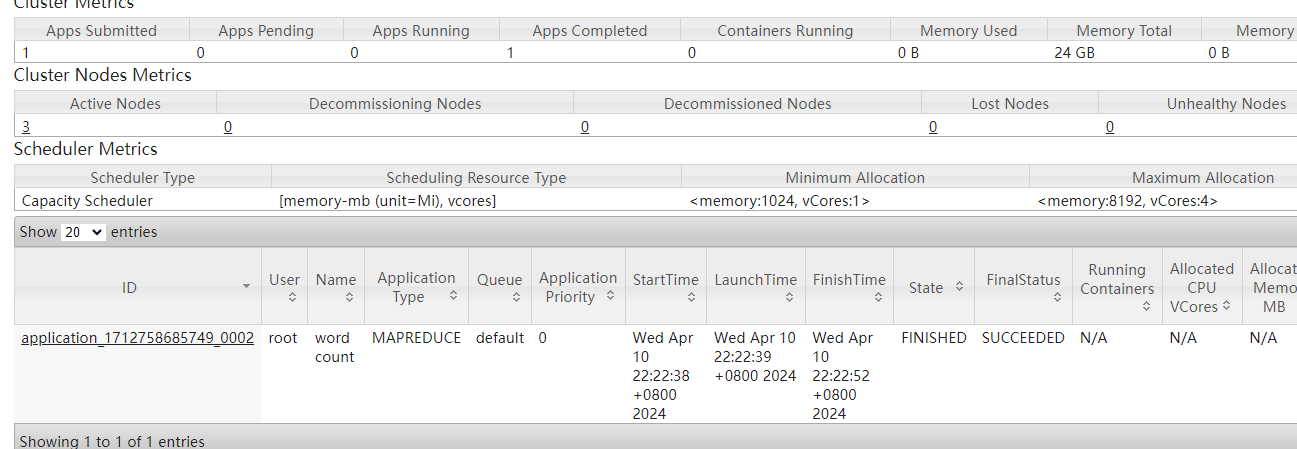
7.6 测试 yarn 资源的调度 和mapreduce 计算
在centos73上执行
在此路径下
/data/soft/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar
hadoop jar /data/soft/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput /wcoutput
# 解释 wordcount 是指程序里面的东西
/wcinput 这个文件夹必须存在,不存在会报错。可以用下面的命令执行
hadoop fs -mkdir /wcinput
/wcoutput 目标文件夹要求不存在,执行的时候会自动创建
如果执行不了的话 扩大虚拟机内存以及
7.7 集群异常操作
在centos72上操作
stop-dfs.sh
在centos73上操作
stop-yarn.sh
在每台机器上操作 初始化生成的 data文件夹 和 log文件夹 hdfs namenode -format
删除生成的data文件夹 和 log文件夹
/data/soft/hadoop/data
/data/soft/hadoop/hadoop/logs
然后
在centos72 上执行
hdfs namenode -format
start-dfs.sh
在centos73 上执行
start-yarn.sh
7.8 配置计算的历史按钮
mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置历史服务器端地址内部通讯地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>centos72:10020</value>
</property>
<!-- 配置历史服务器端web地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>centos72:19888</value>
</property>
</configuration>
- 分发到所有的服务器
xsync.sh mapred-site.xml
在centos73上将yarn 关掉并重启
在centos72上启动历史服务器
mapred --daemon start historyserver mapred stop historyserver 查看是否正常启动 [root@centos72 sbin]# jps 9889 DataNode 9602 NameNode 24948 NodeManager 28055 JobHistoryServer 28750 Jps查看JobHIstory
centos72:19888/jobhistory在centos73上执行 hadoop fs -mkdir /wcinput3 hadoop jar /data/soft/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput3 /wcoutput3
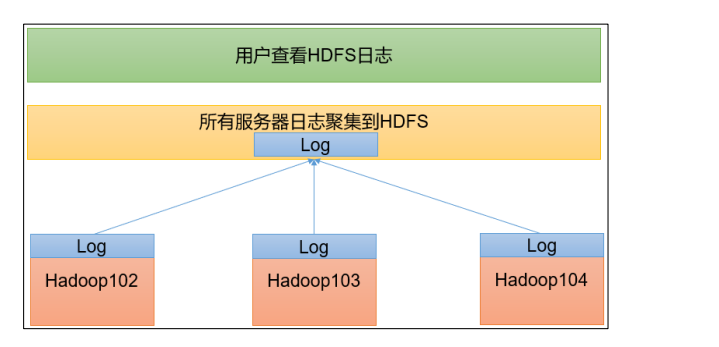
7.9 配置日志的聚集功能
| 应用运行完成以后,将程序运行日志信息上传到 HDFS 系统上
7.10 配置yarn-site.xml
1、在该文件里面增加配置
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
2、分发配置
cd /data/soft/hadoop/hadoop/etc/hadoop
xsync.sh yarn-site.xml
3、关闭NodeManager ResouceManager 和HistoryServer
#centos72 上执行
cd /data/soft/hadoop/hadoop/sbin
mapred --daemon stop historyserver
#centos73 上执行
cd /data/soft/hadoop/hadoop/sbin
stop-yarn.sh
#centos72上执行
mapred --daemon start historyserver
#centos73 上执行
start-yarn.sh
3、删除已经存在的文件
hadoop fs -rm -r /wcoutput*
#运行
hadoop jar /data/soft/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
http://centos72:19888/jobhistory 查看最新一条 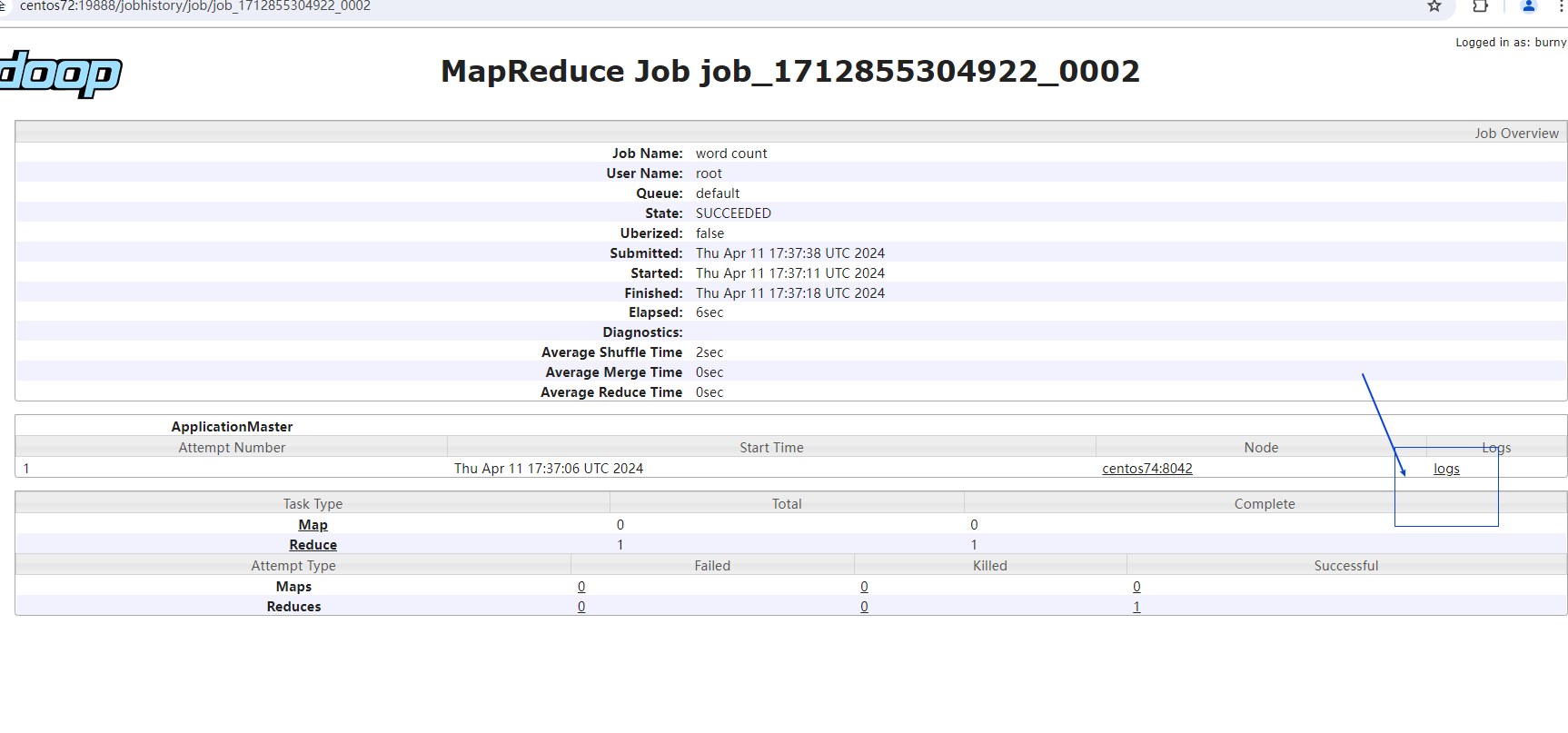
7.11 常用脚本
整体启动
# HDFS
start-dfs.sh / stop-dfs.sh
# YARN
start-yarn.sh /stop-yarn.sh
各个服务组件启动
#HDFS
hdfs --daemon start/sotp namenode/datanode/secondarynamenode
# YARN
yarn --daemon start/sotp resourcemanager/nodemanager
批量脚本
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop 集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh centos72 "/data/soft/hadoop/hadoop/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh centos73 "/data/soft/hadoop/hadoop/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh centos72 "/data/soft/hadoop/hadoop/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop 集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh centos72 "/data/soft/hadoop/hadoop/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh centos73 "/data/soft/hadoop/hadoop/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh centos72 "/data/soft/hadoop/hadoop/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
如果遇到这样子的问题下 可以执行下换行符
-bash: /home/burny/ba/myHadoop.sh: /bin/bash^M: bad interpreter: No such file or directory
原因:错误通常发生在尝试在Unix-like系统上运行脚本文件时,该文件是在Windows环境下编辑的。Windows使用回车换行符(CRLF,即\r\n),而Unix使用换行符(LF,即\n)。在这种情况下,文件中的换行符被错误地转换成了回车符(Carriage Return,即\r),这就导致了脚本解释器路径的错误。
sed -i 's/\r//' your_script.sh
7.12 常用的端口号说明
| 端口号名称 | Hadoop3.x |
|---|---|
| NameNode内部通信端口 | 8020/9000/9820 |
| NameNode外部通信端口 | 9870 |
| MapReduce查看执行任务端口 | 8088 |
| 历史服务器通信端口 | 19888 |
7.13 同步服务器时间
yum install -y ntp && ntpdate ntp3.aliyun.com && timedatectl set-timezone Asia/Shanghai && systemctl restart ntpd && date
7、HDFS 详解
7.1 概述
7.1.1 特点
- 分布式文件管理系统
- 一次写入,多次读出
7.1.2 优缺点
优点:
- 数据自动保存多个副本,提高容错率
- 适合处理大数据 数据规模:能够处理数据规模达到GB TB PB 级别的数据 为念规模:能够处理百万规模以上的文件数量,数量相当于大
- 可以构建在廉价的机器上 缺点:
- 不适合低延时数据访问
- 无法搞笑的对大量小文件进行存储
- 不支持并发写入、文件随机遂改 一个文件只能有一个写,不允许多个线程同时写 仅支持数据append ,不支持文件的随机需改
7.1.2 组成架构
NameNode(nn)
就是master ,他是一个主管、管理者
- 管理HDFS的名称空间
- 配置副本策略
- 管理数据块映射信息
- 处理客户端读写请求
- DataNode . 就是Slave,NN下达命令,DataNode执行实际的操作
- 存储实际的数据块
- 执行数据块的读/写的操作
3.Client
- 文件切片。文件上传HDFS的时候,Client将文件切分成一个一个Bolock ,然后进行上传。
- 与NameNode交互,获取文件的位置信息
- 与DataNode交互,读取或者写入数据
- Client提供一些命令来管理HDFS ,比如NameNode格式化
- Client 可以通过一些命令来访问HDFS,比如增删改查操作
4.Secondary NameNode 并非NameNode的热备份,当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务
- 辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送到NameNode
- 在紧急的情况下,可辅助恢复NameNode
7.1.3 文件块的大小
HDFS 中的为念在物理上是分块存储(Block) ,块的大小可以通过配置参数dfs.block 来规定,默认大小在Hadoop的版本128m
| 为什么块的大小不能设置太小,也不能设置太大
- HDFS 的块设置太小,会增加寻址时间,程序一直在找块的开始位置
- 如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块位置所需的时间。导致程序在处理这块数据时,会非常慢
7.2 HDFS的Shell相关操作
hadoop fs 具体命令 or hdfs dfs 具体命令
7.2.1查看帮助命令
hadoop fs
hadoop fs --help 具体命令
分为三类命令
- 上传
- 下载
- 直接操作HDFS
7.2.2 上传
# 创建文件夹
hadoop fs -mkdir /sanguo
#
echo shuguo > shuguo.txt
# 上传本地文件
# 剪切
hadoop fs -moveFromLocal shuguo.txt /sanguo
# 复制
hadoop fs -copyFromLocal shuguo.txt /sanguo
hadoop fs -put shuguo.txt /sanguo 跟上面一样的复制
# 追加一个文件到已存在的文件末尾
echo liubei > liubei.txt
hadoop fs -appendToFile liubei.txt /sanguo/shuguo.txt
7.2.3 下载
# 从HDFS拷贝到本地
hadoop fs -copyToLocal /sanguo/shuduo.txt ./
=
hadoop fs -get /sanguo/shuguo.txt ./shuguo2.txt
7.2.4 直接操作
#查看目录信息
hadoop fs -ls /sanguo
hadoop fs -cat /sanguo/shuguo.txt
# -chgrp -chmod -chown
hadoop fs -chmod 777 /sanguo/shuguo.txt
# 创建文件夹
hadoop fs mkdir /jinguo
# 复制
hadoop fs -cp /sanguo/shuguo.txt /jinguo/
# 剪切
hadoop fs -mv /sanguo/wuguo.txt /jinguo/
# 显示一个文件末尾1kb的数据
hadoop fs -tail /jinguo/shuguo.txt
# 删除文件或文件夹
hadoop fs -rm /sanguo
hadoop fs -rm -r /sanguo #递归删除
# 统计文件夹大小
hadoop fs -du -s /jinguo
hadoop fs -du -h /jinguo
27 81 /jinguo
27表示文件大小 81 表示27*3 个副本 /jinguo 表示查看的目录
# 设置HDFS 文件中的副本数量
hadoop fs -setrep 10 /jinguo/shuguo.txt
这里设置的副本数只是记录在NameNode 中的元数据中,是否真的会有这么多的副本,目前只有3台设备,罪过也就3个副本,只有节点数的增加到10 台时,副本数采能达到10
https://blog.csdn.net/lvoelife/article/details/133349627
7.3 HDFS的客户端API
7.3.1 下载客户端 (经测试,此步骤可要可不要)
https://github.com/selfgrowth/apache-hadoop-3.1.1-winutils
下载完需要配置一下环境变量

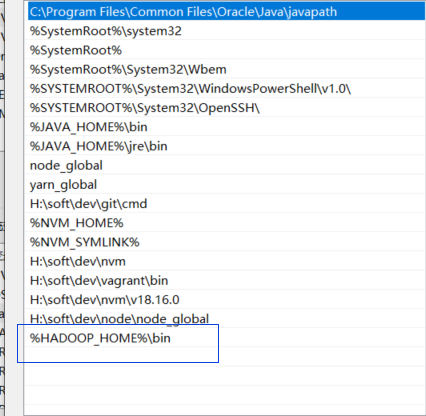
配置完成之后双击一下 bin/winutils.exe 一闪而过是正常的
其他版本建议在 以下地方下载
https://github.com/kontext-tech/winutils
https://github.com/cdarlint/winutils
7.3.2 配置优先级别
由高到低 hdfs-default.xml hdfs-site.xml 在项目资源目录下的配置文件 代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import java.io.IOException;
public class HDFSUtils {
static FileSystem fs = null;
// 完成上传功能
public static void upload(String path_str,String path_str1) throws IOException {
//上传文件到HDFS
//path_str本地文件路径 path_str1是上传到HDFS文件路径
fs.copyFromLocalFile(new Path(path_str),new Path(path_str1));
// 关闭资源
//fs.close();
System.out.println("文件上传成功");
}
// 完成下载文件
public static void downloal(String path_str,String path_str1) throws IOException {
//从 HDFS 下载文件到本地
//path_str是HDFS文件路径 path_str1本地文件路径
fs.copyToLocalFile(new Path(path_str),new Path(path_str1));
// 关闭资源
//fs.close();
System.out.println("文件下载成功");
}
// 创建目录
public static void mkdir(String path_str) throws IOException {
//path_str所要创建目录路径
Path path = new Path(path_str);
boolean exists = fs.exists(path);
if (!exists){
fs.mkdirs(path);
}
// fs.mkdirs();
// 关闭资源
//fs.close();
System.out.println("创建目录成功");
}
// 重命名文件夹
public static void rename(String old_name,String new_path) throws IOException {
//old_name原文件名路径 //new_path新文件名路径
fs.rename(new Path(old_name),new Path(new_path));
// 关闭资源
//fs.close();
System.out.println("重命名文件夹成功");
}
//main()方法中调用
// rename("/aa","/aa2"); //重命名文件夹
// 删除文件 ,如果是非空文件夹,参数2必须给值true
public static void delete(String path_str) throws IOException {
//ture表示递归删除 可以用来删除目录 rm -rf
//false表示非递归删除
fs.delete(new Path(path_str),true);
// 关闭资源
//fs.close();
System.out.println("删除文件夹成功");
}
// 查看文件信息
public static void listFiles(String path_str) throws IOException {
//获取迭代器对象
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path(path_str),true);
//遍历
while (listFiles.hasNext()){
LocatedFileStatus fileStatus = listFiles.next();
//打印当前文件名
System.out.println(fileStatus.getPath().getName());
//打印当前文件块大小
System.out.println(fileStatus.getBlockLocations());
//打印当前文件权限
System.out.println(fileStatus.getPermission());
//打印当前文件内容长度
System.out.println(fileStatus.getLen());
//获取该文件块信息(包含长度、数据块、datanode的信息)
// BlockLocation[] blockLocations = fileStatus.getBlockLocations();
// for (BlockLocation bl : blockLocations){
// System.out.println("block-length:" + bl.getLength()+"--"+"block-offset:"+bl.getOffset());
// String[] hosts = bl.getHosts();
// for (String host : hosts){
// System.out.println(host);
// }
// }
}
System.out.println("--------分割线---------");
//fs.close();
}
//把查看文件信息分解为下面几个方法
// 1、统计目录下所有文件(包括子目录)
// 1、统计某个路径(由main方法决定哪个路径),下所有的文件数里,例如:输出:该路径下共有 3 个文件
public static void count(String path_str) throws IOException {
//获取迭代器对象
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path(path_str),true);
//遍历
int count = 0;
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
count++;
}
System.out.println("路径:【"+ path_str +"】下,文件数量为"+count);
//fs.close();
}
// 2、列出某个路径(由main方法决定哪个路径),下所有的文件数里,例如:文件1,文"路径:【"+ path_str +"】下,文件有:"+件2,....
public static void fileList(String path_str) throws IOException {
//获取迭代器对象
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path(path_str),true);
String res = "";
//遍历
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
res += fileStatus.getPath().getName() + ", ";
}
if (res.equals("")){
res = "没有文件";
}else {
res = res.substring(0,res.length() - 2);
}
System.out.println("路径:【"+ path_str +"】下的文件:" + res);
// //fs.close();
}
/* 路径【/】下共有 7 子文件
文件数量:1,文件列表:data.txt
目录数量:6,文件列表:a, exp, input, output, test, tmp*/
public static void list(String path) throws IOException {
FileStatus[] fileStatuses = fs.listStatus(new Path(path));
String res = "路径【" + path + "】下共有 " + fileStatuses.length + " 子文件";
int file_num = 0;
String file_list = "";
int dir_num = 0;
String dir_list = "";
for (FileStatus fileStatus:fileStatuses){
if (fileStatus.isFile()){
file_num ++;
file_list += fileStatus.getPath().getName() + ", ";
}else {
dir_num ++;
dir_list += fileStatus.getPath().getName() + ", ";
}
}
if (file_num != 0) res += "\n\t文件数量:" + file_num + ",文件列表:" + file_list.substring(0,file_list.length()-2);
if (dir_num != 0) res += "\n\t目录数量:" + dir_num + ",文件列表:" + dir_list.substring(0,dir_list.length()-2);
System.out.println(res);
}
// 检查路径是目录还是文件
public static void mulu(String path_str) throws IOException {
Path path = new Path(path_str);
// 判断路径是否存在
if (fs.exists(path)) {
// 获取指定路径的详细信息
FileStatus status = fs.getFileStatus(path);
if (status.isDirectory()) {
System.out.println(path + "这是一个目录");
} else if (status.isFile()) {
System.out.println(path + "这是一个文件");
} else {
System.out.println("这是一个未知类型");
}
} else {
System.out.println("路径不存在");
}
//关闭资源
// //fs.close();
}
//调用
public static void main(String[] args) throws IOException {
// 初始化客户端对象
//构造一个配置对象,设置一个参数:访问的 HDFS 的 URL
Configuration conf = new Configuration();
//这里指定使用的是 HDFS
conf.set("fs.defaultFS","hdfs://centos72:8020");
//通过如下的方式进行客户端身份的设置
System.setProperty("HADOOP_USER_NAME","root");
//通过 FileSystem 的静态方法获取文件系统客户端对象
fs = FileSystem.get(conf); //抛出异常
System.out.println("hdfs连接成功");
//main()方法中调用
list("/"); //查看所有
//main()方法中调用
fileList("/"); //查看有什么文件
fileList("/input"); //查看有什么文件
//main()方法中调用
count("/"); //统计
//main()方法中调用
mulu("/exp/word.txt"); //检查路径是目录还是文件
//main()方法中调用
listFiles("/data.txt"); //查看文件信息
//main()方法中调用
delete("/aa2"); //删除文件
//main()方法中调用
rename("/aa","/aa2"); //重命名文件夹
//main()方法中调用
// upload("D:/大数据/word.txt","/input"); //上传
//main()方法中调用
mkdir("/input"); //创建目录
//main()方法中调用
// downloal("/data.txt","D:/大数据/文件"); //下载
}
}