Kubernetes(k8s)
大纲
k8s概念和架构
从零开始搭建集群
基于集群部署工具 kubeadm
基于二进制包方式
- 核心概念
- Pod
- 控制器
- 存储
- service
- 调度器
- 安全机制RBAC
- 包管理工具Helm等等
集群监控平台系统
高可用k8s集群
集群环境中部署项目
功能和架构
概述
Kubernetes 是一个轻便的和可扩展的开源平台,用于管理容器化应用和服务。通过Kubernetes 能够进行应用的自动化部署和扩缩容。在Kubernetes 中,会将组成应用的容器组合成一个逻辑单元以更易管理和发现。Kubernetes 积累了作为Google 生产环境运行工作负载15 年的经验,并吸收了来自于社区的最佳想法和实践。
功能
自动装箱
基于容器对应用运行环境的资源配置要求自动部署应用容器
自我修复(自愈能力)
当容器失败时,会对容器进行重启
当所部署的Node 节点有问题时,会对容器进行重新部署和重新调度
当容器未通过监控检查时,会关闭此容器直到容器正常运行时,才会对外提供服务
水平扩展
通过简单的命令、用户UI 界面或基于CPU 等资源使用情况,对应用容器进行规模扩大或规模剪裁
服务发现
用户不需使用额外的服务发现机制,就能够基于Kubernetes 自身能力实现服务发现和负载均衡
滚动更新
可以根据应用的变化,对应用容器运行的应用,进行一次性或批量式更新
版本回退
可以根据应用部署情况,对应用容器运行的应用,进行历史版本即时回退
密钥和配置管理
在不需要重新构建镜像的情况下,可以部署和更新密钥和应用配置,类似热部署
存储编排
自动实现存储系统挂载及应用,特别对有状态应用实现数据持久化非常重要存储系统可以来自于本地目录、网络存储(NFS、Gluster、Ceph 等)、公共云存储服务
批处理
提供一次性任务,定时任务;满足批量数据处理和分析的场景
k8s架构组件
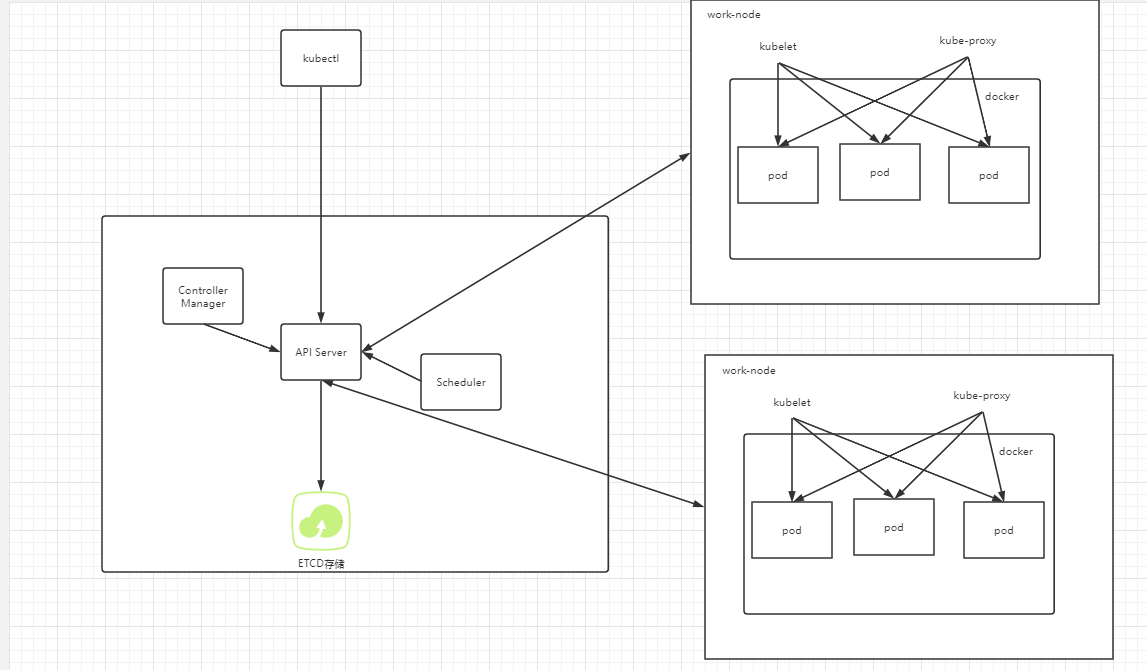
- Master Node k8s 集群控制节点,对集群进行调度管理,接受集群外用户去集群操作请求;
API Server(Restflul方式)Scheduler(节点调度,选择node节点应用部署)ClusterState Store(ETCD数据库)Controller MangerServer处理集群中常规后台任务,一个资源对应一个控制器
- Worker Node 集群工作节点,运行用户业务应用容器;
kubeletmaster 派到 node节点代表,不按理本机容器kube proxy网络代理,负载均衡ContainerRuntime
核心概念
Pod
- 最小部署单元
- 一组容器的集合
- 一个pod是共享网络的
- 是由多个容器组成
- 生命周期是短暂的
Controller
- 确保预期的pod的副本数量
- 无状态应用部署(不依赖存储数据)
- 有状态应用部署(依赖特定的存储 ,ip)
- 确保所有的node 运行同一个pod
- 一次性任务和定时任务
Service
- 定义一组pod的访问规则
搭建k8s集群
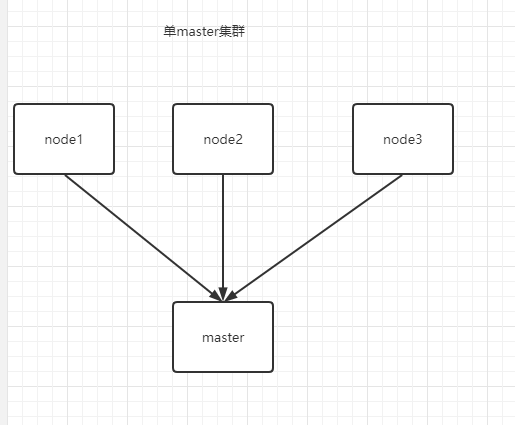
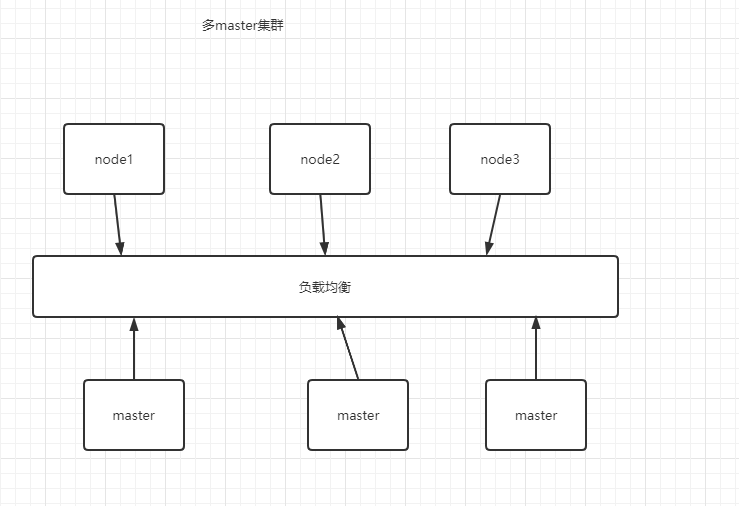
平台规划
- 单节点master
- 多节点master
部署方式
- kubeadm
是一个k8s部署的工具,提供kubeadm init(创建一个master节点) 和kubeadm join masterNodeIP(将node节点加入到当前集群中) 用户快速部署集群
- 二进制包
从github下载发行的二进制包,需要部署每个组件,组成集群
比较:
kubeadm 降低部署门槛,屏蔽了很多细节,但是遇到问题难排查。
二进制包手动部署麻烦点,可以学习很多工作原理,有利于后期维护
推荐:二进制包安装。
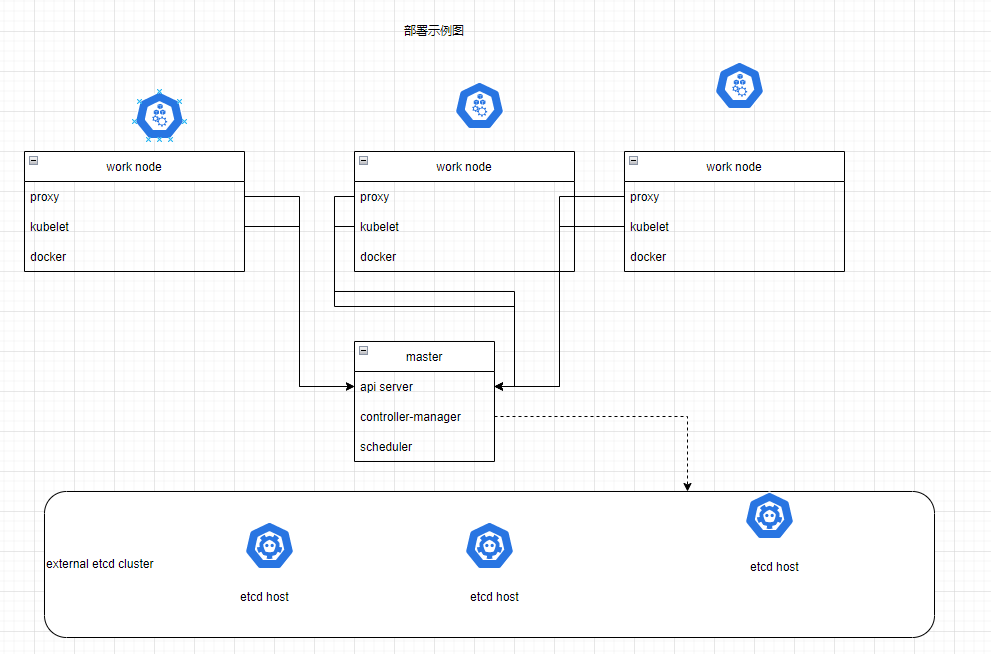
最终目标
- 在所有的节点上安装docker和kubeadm
- 部署Kubernetes Master
- 部署容器网络插件
- 部署Kubernetes Node ,将节点加入Kubernetes集群中
- 部署Dashboard Web界面,可视化查看Kubernetes资源
kubeadm 部署
系统初始化
笔者本来是用centos9进行实验,但是一直有问题也百度不到答案。更换为了centos7实验
# 各个机器用户名 以及 机器ip
master 192.168.1.3
node1 192.168.1.5
node2 192.168.1.6
# 每个机器都执行,除了特殊说明外
# 关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
#关闭selinux
sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久
setenforce 0 # 临时
#关闭swap
swapoff -a # 临时
sed -ri 's/.*swap.*/#&/' /etc/fstab # 永久
#在各个机器上单独设置主机名
hostnamectl set-hostname master
hostnamectl set-hostname node1
hostnamectl set-hostname node2
#添加hosts
cat >> /etc/hosts <<EOF
192.168.1.3 master
192.168.1.5 node1
192.168.1.6 node2
EOF
#同一节点的不同pod是利用linux bridge在网路的第二层进行通讯,
# 如果不进行设置的话,podA请求services通过iptables发送,services中的podB返回数据时发现podA与podB在同一节点会走网路的第二层进行返回。
#由于没有原路返回造成podA请求services时的session无法收到返回值而连接超时,所以需要进行设置让第二层的bridge在转发时也通过第三层的 iptables进行通信。
#将桥接的IPv4流量传递到iptables的链上
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
#使网络生效
# 同步时间 此步忽略,后续待研究
#centos7 之前有 ntpdate centos8 之后没有了 替代品为 chrony
yum update -y && yum makecache && yum install -y yum-utils
yum install ntpdate -y && ntpdate time.windows.com
所有机器上安装 docker /kubeadm /kubelet
yum remove docker docker-client docker-client-latest docker-common docker-latest docker-latest-logrotate docker-logrotate docker-engine && yum update -y && yum install -y yum-utils && yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
#2.2 替代掉原来的仓库
sed -i 's+download.docker.com+mirrors.aliyun.com/docker-ce+' /etc/yum.repos.d/docker-ce.repo
#3.
#3.1 centos8 之前是 yum makecache fast
#3.2 podman 容器与docker 冲突 ,删除podman(这个后续再了解有关系)
#问题: 安装的软件包的问题 buildah-1:1.27.0-2.el9.x86_64
# - 软件包 buildah-1:1.27.0-2.el9.x86_64 需要 runc >= 1.0.0-26,但没有提供者可以被安装
# - 软件包 containerd.io-1.6.6-3.1.el9.x86_64 与 runc(由 runc-4:1.1.3-2.el9.x86_64 提供)冲突
# - 软件包 containerd.io-1.6.6-3.1.el9.x86_64 淘汰了 runc 提供的 runc-4:1.1.3-2.el9.x86_64
#centos8 需要执行,centos7不用执行
rpm -q podman && yum erase podman buildah
# 都需要执行
yum makecache && yum -y install docker-ce && systemctl enable docker && systemctl start docker
# 镜像加速 ,阿里云搜索镜像,进入控制台,个人版, 右边镜像加速器,查看个人的加速地址
# 修改系统的加速地址
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://nx698r4f.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
#安装kubelet kubeadm kubectl
# 添加yum源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
yum install -y kubelet kubeadm kubectl
systemctl enable kubelet
#kubelet :运行在cluster,负责启动pod管理容器
#kubeadm :k8s快速构建工具,用于初始化cluster
#kubectl :k8s命令工具,部署和管理应用,维护组件
# 到了这里需要重启系统
节点部署
此步骤非常重要,这是笔者耗时最久的步骤,耗时两天,刚好是周六日
回来总结下收获:这个步骤给笔者有了大概一个概念,和掌握几个查看日志的命令
此处需要说明的几个重要概念和命令
# 查看某项服务的日志
journalctl -xeu 服务名
# 查看某个容器的日志
crictl logs -f 容器id
#初始化失败重置命令
#可以在任一node上执行
kubeadm reset -f && rm -fr ~/.kube/ /etc/kubernetes/* var/lib/etcd/* #
#k8s已经从1.20 开始用container了,而不是docker .具体可以查看下百度
#container 的命令开头为ctr xxx 类似于 docker xxx
# 其中还有 crictl命令 ,是k8s 基于ctr 的一些命令进行封装。# 此处说法大概是这样,但是又有区别,具体右面再边写文档边积累。以下博客可以查看下ctr 和crictl 命令
# ctictl 命令
https://blog.csdn.net/qq_32907195/article/details/126518761
#ctr是containerd的一个客户端工具
#crictl 是 CRI 兼容的容器运行时命令行接口,可以使用它来检查和调试 Kubernetes 节点上的容器运行时和应用程序,是基于ctr进行封装
#crictl 使用命名空间 k8s.io,即crictl image list = ctr -n=k8s.io image list
#是基于ctr进行封装
# 部署master节点
# cidr 代表网段 只要跟当前网络不冲突即可
# apiserver 当前机器的ip
# 执行之前需要确保CPU至少两核。在虚拟机 设置 --常规--处理器,调整为2核CPU
# 查看版本
[root@master ~]# kubelet --version
Kubernetes v1.25.3
[root@master ~]# kubeadm version
kubeadm version: &version.Info{Major:"1", Minor:"25", GitVersion:"v1.25.3", GitCommit:"434bfd82814af038ad94d62ebe59b133fcb50506", GitTreeState:"clean", BuildDate:"2022-10-12T10:55:36Z", GoVersion:"go1.19.2", Compiler:"gc", Platform:"linux/amd64"}
#注意此处只能在master节点上运行命令,将version更改为1.25.3
# 经历过很多次失败,调整了下安装顺序,可按照笔者叙述顺序执行
# 1.查看containerd 注意:k8s已经从1.20 开始用container了,而不是docker .具体可以查看下百度
# 1.1 问题
[root@node1 ~]# crictl images
WARN[0000] image connect using default endpoints: [unix:///var/run/dockershim.sock unix:///run/containerd/containerd.sock unix:///run/crio/crio.sock unix:///var/run/cri-dockerd.sock]. As the default settings are now deprecated, you should set the endpoint instead.
ERRO[0000] unable to determine image API version: rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial unix /var/run/dockershim.sock: connect: no such file or directory"
E1106 15:00:14.880884 28750 remote_image.go:125] "ListImages with filter from image service failed" err="rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.ImageService" filter="&ImageFilter{Image:&ImageSpec{Image:,Annotations:map[string]string{},},}"
FATA[0000] listing images: rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.ImageService
#1.2 原因 有错误,是还没有配置containerd
#1.3 解决方案
containerd config default > /etc/containerd/config.toml
crictl config runtime-endpoint unix:///run/containerd/containerd.sock
crictl config image-endpoint unix:///run/containerd/containerd.sock
systemctl restart containerd
#查看要下载的镜像
kubeadm config images list
registry.k8s.io/kube-apiserver:v1.25.3
registry.k8s.io/kube-controller-manager:v1.25.3
registry.k8s.io/kube-scheduler:v1.25.3
registry.k8s.io/kube-proxy:v1.25.3
registry.k8s.io/pause:3.8
registry.k8s.io/etcd:3.5.4-0
registry.k8s.io/coredns/coredns:v1.9.3
# 下载镜像--阿里镜像 ,coredns 路径有点区别
crictl pull registry.aliyuncs.com/google_containers/kube-apiserver:v1.25.3
crictl pull registry.aliyuncs.com/google_containers/kube-controller-manager:v1.25.3
crictl pull registry.aliyuncs.com/google_containers/kube-scheduler:v1.25.3
crictl pull registry.aliyuncs.com/google_containers/kube-proxy:v1.25.3
crictl pull registry.aliyuncs.com/google_containers/pause:3.8
crictl pull registry.aliyuncs.com/google_containers/etcd:3.5.4-0
crictl pull registry.aliyuncs.com/google_containers/coredns:v1.9.3
# 更换名字
ctr -n k8s.io i tag registry.aliyuncs.com/google_containers/kube-apiserver:v1.25.3 registry.k8s.io/kube-apiserver:v1.25.3
ctr -n k8s.io i tag registry.aliyuncs.com/google_containers/kube-controller-manager:v1.25.3 registry.k8s.io/kube-controller-manager:v1.25.3
ctr -n k8s.io i tag registry.aliyuncs.com/google_containers/kube-scheduler:v1.25.3 registry.k8s.io/kube-scheduler:v1.25.3
ctr -n k8s.io i tag registry.aliyuncs.com/google_containers/kube-proxy:v1.25.3 registry.k8s.io/kube-proxy:v1.25.3
ctr -n k8s.io i tag registry.aliyuncs.com/google_containers/pause:3.8 registry.k8s.io/pause:3.8
ctr -n k8s.io i tag registry.aliyuncs.com/google_containers/etcd:3.5.4-0 registry.k8s.io/etcd:3.5.4-0
ctr -n k8s.io i tag registry.aliyuncs.com/google_containers/coredns:v1.9.3 registry.k8s.io/coredns/coredns:v1.9.3
# 2 初始化
# 执行以下命令需要稍等一会儿
# –image-repository string: ,默认值是k8s.gcr.io
# –kubernetes-version string: 指定kubenets版本号, 执行命令 kubelet --version 获得
# –apiserver-advertise-address 指明用 Master 的哪个 interface 与 Cluster 的其他节点通信。如果 Master 有多个 interface,建议明确指定,如果不指定,kubeadm 会自动选择有默认网关的 interface。
# –pod-network-cidr 指定 Pod 网络的范围。Kubernetes支持多种网络方案,而且不同网络方案对 –pod-network-cidr有自己的要求,这里设置为10.244.0.0/16
# 两个ip地址不冲突即可
kubeadm init \
--apiserver-advertise-address=192.168.1.3 \
--image-repository registry.aliyuncs.com/google_containers \
--service-cidr=10.1.0.0/16 \
--kubernetes-version v1.25.3 \
--pod-network-cidr=10.244.0.0/16
# 2.1 问题
[kubelet-check] Initial timeout of 40s passed.
# 2.2 如何排查
# kubelet 是基于containerd 进行执行等,
journalctl -xeu kubelet >> b.txt
journalctl -xeu containerd >> a.txt
#2.3
# 在当前位置查看 a.txt 和 b.txt文件
#2.4
# 查看当前路径下a.txt中的报错信息 下述简称报错1
11月 05 21:34:04 master containerd[204102]: time="2022-11-05T21:34:04.444635983+08:00" level=error msg="RunPodSandbox for &PodSandboxMetadata{Name:kube-controller-manager-master,Uid:1ab5ceb5a63fb5f500a8507ef20d279d,Namespace:kube-system,Attempt:0,} failed, error" error="failed to get sandbox image \"registry.k8s.io/pause:3.6\": failed to pull image \"registry.k8s.io/pause:3.6\": failed to pull and unpack image \"registry.k8s.io/pause:3.6\": failed to resolve reference \"registry.k8s.io/pause:3.6\": failed to do request: Head \"https://us-west2-docker.pkg.dev/v2/k8s-artifacts-prod/images/pause/manifests/3.6\": dial tcp 142.250.157.82:443: i/o timeout"
11月 05 21:34:04 master containerd[204102]: time="2022-11-05T21:34:04.448494829+08:00" level=error msg="RunPodSandbox for &PodSandboxMetadata{Name:kube-scheduler-master,Uid:98df219f5cfeca96e25bb6066181889b,Namespace:kube-system,Attempt:0,} failed, error" error="failed to get sandbox image \"registry.k8s.io/pause:3.6\": failed to pull image \"registry.k8s.io/pause:3.6\": failed to pull and unpack image \"registry.k8s.io/pause:3.6\": failed to resolve reference \"registry.k8s.io/pause:3.6\": failed to do request: Head \"https://us-west2-docker.pkg.dev/v2/k8s-artifacts-prod/images/pause/manifests/3.6\": dial tcp 142.250.157.82:443: i/o timeout"
# 查看到b.txt中的报错信息 下述简称报错2
11月 05 21:34:23 master kubelet[566349]: E1105 21:34:23.025253 566349 eviction_manager.go:256] "Eviction manager: failed to get summary stats" err="failed to get node info: node \"master\" not found"
11月 05 21:34:23 master kubelet[566349]: E1105 21:34:23.095570 566349 kubelet.go:2448] "Error getting node" err="node \"master\" not found"
11月 05 21:34:23 master kubelet[566349]: E1105 21:34:23.170230 566349 kubelet.go:2373] "Container runtime network not ready" networkReady="NetworkReady=false reason:NetworkPluginNotReady message:Network plugin returns error: cni plugin not initialized"
11月 05 21:34:23 master kubelet[566349]: E1105 21:34:23.203701 566349 kubelet.go:2448] "Error getting node" err="node \"master\" not found"
#2.5
# 报错1中可以获得,是没有3.6这个镜像
#查看当前镜像,发现有一个3.8的
[root@master ~]# crictl images
IMAGE TAG IMAGE ID SIZE
registry.aliyuncs.com/google_containers/coredns v1.9.3 5185b96f0becf 14.8MB
registry.aliyuncs.com/google_containers/etcd 3.5.4-0 a8a176a5d5d69 102MB
registry.aliyuncs.com/google_containers/kube-apiserver v1.25.3 0346dbd74bcb9 34.2MB
registry.aliyuncs.com/google_containers/kube-controller-manager v1.25.3 6039992312758 31.3MB
registry.aliyuncs.com/google_containers/kube-proxy v1.25.3 beaaf00edd38a 20.3MB
registry.aliyuncs.com/google_containers/kube-scheduler v1.25.3 6d23ec0e8b87e 15.8MB
registry.aliyuncs.com/google_containers/pause 3.8 4873874c08efc 311kB
#2.6
# 仿照这个镜像名 和tag 拉取一个3.6的
crictl pull registry.aliyuncs.com/google_containers/pause:3.6
#2.7
#然后更改镜像名称, 为什么是 registry.k8s.io/pause:3.6 。主要是看日志,2.4中的日志有提到
ctr -n k8s.io i tag registry.aliyuncs.com/google_containers/pause:3.6 registry.k8s.io/pause:3.6
#2.8
#已经解决了问题1,需要重置以下并删除配置文件,并重启以下
kubeadm reset -f && rm -fr ~/.kube/ /etc/kubernetes/* var/lib/etcd/*
systemctl restart containerd
systemctl restart kubelet
#2.9
# 再初始化一下
kubeadm init \
--apiserver-advertise-address=192.168.1.3 \
--image-repository registry.aliyuncs.com/google_containers \
--service-cidr=10.1.0.0/16 \
--kubernetes-version v1.25.3 \
--pod-network-cidr=10.244.0.0/16 \
--ignore-preflight-errors=Swap
# 发现可以了,创建成功 ,详细见下面,单独弄结果出来的,
#2.10
# 再看下日志
journalctl -xeu kubelet > b.txt
journalctl -xeu containerd > a.txt
# 发现containerd已经没有报错了,但是kubelet还有报错,此处没法子,只能继续往下走
11月 06 15:26:51 master kubelet[21874]: E1106 15:26:51.533461 21874 kuberuntime_manager.go:954] "Failed to stop sandbox" podSandboxID={Type:containerd ID:6fd3061e3b444d4b69136d196d73ac4c7f6826241b969c980c3ce46bbf27c2fb}
11月 06 15:26:51 master kubelet[21874]: E1106 15:26:51.533897 21874 kuberuntime_manager.go:695] "killPodWithSyncResult failed" err="failed to \"KillPodSandbox\" for \"9ed4a7e8-8ea3-4aa1-a762-9f5d8ab71392\" with KillPodSandboxError: \"rpc error: code = Unknown desc = failed to destroy network for sandbox \\\"6fd3061e3b444d4b69136d196d73ac4c7f6826241b969c980c3ce46bbf27c2fb\\\": plugin type=\\\"calico\\\" failed (delete): stat /var/lib/calico/nodename: no such file or directory: check that the calico/node container is running and has mounted /var/lib/calico/\""
11月 06 15:26:51 master kubelet[21874]: E1106 15:26:51.534097 21874 pod_workers.go:965] "Error syncing pod, skipping" err="failed to \"KillPodSandbox\" for \"9ed4a7e8-8ea3-4aa1-a762-9f5d8ab71392\" with KillPodSandboxError: \"rpc error: code = Unknown desc = failed to destroy network for sandbox \\\"6fd3061e3b444d4b69136d196d73ac4c7f6826241b969c980c3ce46bbf27c2fb\\\": plugin type=\\\"calico\\\" failed (delete): stat /var/lib/calico/nodename: no such file or directory: check that the calico/node container is running and has mounted /var/lib/calico/\"" pod="kube-system/coredns-c676cc86f-7ng7k" podUID=9ed4a7e8-8ea3-4aa1-a762-9f5d8ab71392
11月 06 15:27:01 master kubelet[21874]: E1106 15:27:01.514238 21874 remote_runtime.go:269] "StopPodSandbox from runtime service failed" err="rpc error: code = Unknown desc = failed to destroy network for sandbox \"cacb95d85a7f79eb152105c7eab2600bab8eee220beb5e4f8682f99fa7626407\": plugin type=\"calico\" failed (delete): stat /var/lib/calico/nodename: no such file or directory: check that the calico/node container is running and has mounted /var/lib/calico/" podSandboxID="cacb95d85a7f79eb152105c7eab2600bab8eee220beb5e4f8682f99fa7626407"
11月 06 15:27:01 master kubelet[21874]: E1106 15:27:01.514286 21874 kuberuntime_manager.go:954] "Failed to stop sandbox" podSandboxID={Type:containerd ID:cacb95d85a7f79eb152105c7eab2600bab8eee220beb5e4f8682f99fa7626407}
11月 06 15:27:01 master kubelet[21874]: E1106 15:27:01.514362 21874 kuberuntime_manager.go:695] "killPodWithSyncResult failed" err="failed to \"KillPodSandbox\" for \"4679c1ab-ff87-4a9e-8912-d493b9b0cb61\" with KillPodSandboxError: \"rpc error: code = Unknown desc = failed to destroy network for sandbox \\\"cacb95d85a7f79eb152105c7eab2600bab8eee220beb5e4f8682f99fa7626407\\\": plugin type=\\\"calico\\\" failed (delete): stat /var/lib/calico/nodename: no such file or directory: check that the calico/node container is running and has mounted /var/lib/calico/\""
11月 06 15:27:01 master kubelet[21874]: E1106 15:27:01.514419 21874 pod_workers.go:965] "Error syncing pod, skipping" err="failed to \"KillPodSandbox\" for \"4679c1ab-ff87-4a9e-8912-d493b9b0cb61\" with KillPodSandboxError: \"rpc error: code = Unknown desc = failed to destroy network for sandbox \\\"cacb95d85a7f79eb152105c7eab2600bab8eee220beb5e4f8682f99fa7626407\\\": plugin type=\\\"calico\\\" failed (delete): stat /var/lib/calico/nodename: no such file or directory: check that the calico/node container is running and has mounted /var/lib/calico/\"" pod="kube-system/coredns-c676cc86f-x5jfq" podUID=4679c1ab-ff87-4a9e-8912-d493b9b0cb61
11月 06 15:27:06 master kubelet[21874]: E1106 15:27:06.526884 21874 remote_runtime.go:269] "StopPodSandbox from runtime service failed" err="rpc error: code = Unknown desc = failed to destroy network for sandbox \"6fd3061e3b444d4b69136d196d73ac4c7f6826241b969c980c3ce46bbf27c2fb\": plugin type=\"calico\" failed (delete): stat /var/lib/calico/nodename: no such file or directory: check that the calico/node container is running and has mounted /var/lib/calico/" podSandboxID="6fd3061e3b444d4b69136d196d73ac4c7f6826241b969c980c3ce46bbf27c2fb"
11月 06 15:27:06 master kubelet[21874]: E1106 15:27:06.527002 21874 kuberuntime_manager.go:954] "Failed to stop sandbox" podSandboxID={Type:containerd ID:6fd3061e3b444d4b69136d196d73ac4c7f6826241b969c980c3ce46bbf27c2fb}
11月 06 15:27:06 master kubelet[21874]: E1106 15:27:06.527061 21874 kuberuntime_manager.go:695] "killPodWithSyncResult failed" err="failed to \"KillPodSandbox\" for \"9ed4a7e8-8ea3-4aa1-a762-9f5d8ab71392\" with KillPodSandboxError: \"rpc error: code = Unknown desc = failed to destroy network for sandbox \\\"6fd3061e3b444d4b69136d196d73ac4c7f6826241b969c980c3ce46bbf27c2fb\\\": plugin type=\\\"calico\\\" failed (delete): stat /var/lib/calico/nodename: no such file or directory: check that the calico/node container is running and has mounted /var/lib/calico/\""
11月 06 15:27:06 master kubelet[21874]: E1106 15:27:06.527111 21874 pod_workers.go:965] "Error syncing pod, skipping" err="failed to \"KillPodSandbox\" for \"9ed4a7e8-8ea3-4aa1-a762-9f5d8ab71392\" with KillPodSandboxError: \"rpc error: code = Unknown desc = failed to destroy network for sandbox \\\"6fd3061e3b444d4b69136d196d73ac4c7f6826241b969c980c3ce46bbf27c2fb\\\": plugin type=\\\"calico\\\" failed (delete): stat /var/lib/calico/nodename: no such file or directory: check that the calico/node container is running and has mounted /var/lib/calico/\"" pod="kube-system/coredns-c676cc86f-7ng7k" podUID=9ed4a7e8-8ea3-4aa1-a762-9f5d8ab71392
#2.11
#查看容器,
crictl ps
crictl ps -a
[root@master ~]# crictl ps
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID POD
260eea604f0be beaaf00edd38a 35 minutes ago Running kube-proxy 0 abaaf61cc8c3c kube-proxy-m2d2p
c6f60ace89366 0346dbd74bcb9 36 minutes ago Running kube-apiserver 0 820a016a689f8 kube-apiserver-master
819e229b6b646 6039992312758 36 minutes ago Running kube-controller-manager 0 8b17ec811ad84 kube-controller-manager-master
94e7cf8c7c4c0 a8a176a5d5d69 36 minutes ago Running etcd 0 5ded4442546d5 etcd-master
2bd7db5582d76 6d23ec0e8b87e 36 minutes ago Running kube-scheduler 0 789b684d093a0 kube-scheduler-master
[root@master ~]# crictl ps -a
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID POD
3be28e4dffec6 c3fc7e2b20f86 23 minutes ago Exited flexvol-driver 0 36a7cb99da6bd calico-node-7mm8x
7c1c7653d17b5 ab4bfb784a043 23 minutes ago Exited install-cni 0 36a7cb99da6bd calico-node-7mm8x
75d618d0c97f4 ab4bfb784a043 23 minutes ago Exited upgrade-ipam 0 36a7cb99da6bd calico-node-7mm8x
260eea604f0be beaaf00edd38a 35 minutes ago Running kube-proxy 0 abaaf61cc8c3c kube-proxy-m2d2p
c6f60ace89366 0346dbd74bcb9 36 minutes ago Running kube-apiserver 0 820a016a689f8 kube-apiserver-master
819e229b6b646 6039992312758 36 minutes ago Running kube-controller-manager 0 8b17ec811ad84 kube-controller-manager-master
94e7cf8c7c4c0 a8a176a5d5d69 36 minutes ago Running etcd 0 5ded4442546d5 etcd-master
2bd7db5582d76 6d23ec0e8b87e 36 minutes ago Running kube-scheduler 0 789b684d093a0 kube-scheduler-master
#以下是小插曲,可忽略
# 上面使用centos7执行的,一开始笔者是用centos9 stream 执行,
# 由于一开始用的是finalshell ,经常看到左下角的挂载磁盘路径一直在变动
# 又查看了下日志
journalctl -xeu kubelet > b.txt
journalctl -xeu containerd > a.txt
#发现很多都是connect refused 后来确实没找到原因,所以更换为centos7执行
#发现容器全都停止了,但有时候又启动了,这个跟docker里有一个树形 update=true 类似,就是会随着docker的启动而启动,如果启动失败了又会不断自动重启
# 根据上面kubelet 图:依次从下往上查看日志
#etcd -> scheduler -> controllder -> apiserver
crictl logs -f 容器id
#发现大多数报错为
#connect: connection refused
执行结果
[root@master ~]# kubeadm init \
> --apiserver-advertise-address=192.168.1.3 \
> --image-repository registry.aliyuncs.com/google_containers \
> --service-cidr=10.1.0.0/16 \
> --kubernetes-version v1.25.3 \
> --pod-network-cidr=10.244.0.0/16 \
> --ignore-preflight-errors=Swap
[init] Using Kubernetes version: v1.25.3
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master] and IPs [10.1.0.1 192.168.1.3]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost master] and IPs [192.168.1.3 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost master] and IPs [192.168.1.3 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 18.505434 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node master as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node master as control-plane by adding the taints [node-role.kubernetes.io/control-plane:NoSchedule]
[bootstrap-token] Using token: ftc6vs.os97gqzam62s5a0v
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.1.3:6443 --token 0dsy6g.zd0uoselslw8trsz \
--discovery-token-ca-cert-hash sha256:52682768ae891700eec9a8466b03b567c832eae753e800c9cceccea7e60396b8
#根据提示继续在master中操作
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# export KUBECONFIG=/etc/kubernetes/admin.conf
# 此句只会在当前的cmd窗口前生效,为了永久生效 ,故换了下语句,在master中执行
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" > /etc/profile.d/kubeconfig.sh
source /etc/profile.d/kubeconfig.sh
systemctl restart containerd.service
systemctl restart kubelet.service
#分别在节点node1 和node2行执行,此处需要更换,如果不更换会找不到镜像错误,具体可以查看下日志
crictl pull registry.aliyuncs.com/google_containers/pause:3.6
ctr -n k8s.io i tag registry.aliyuncs.com/google_containers/pause:3.6 registry.k8s.io/pause:3.6
# 分别在node1 和node2 执行,此处也需要更换,机器部署前都需要配置下
containerd config default > /etc/containerd/config.toml
crictl config runtime-endpoint unix:///run/containerd/containerd.sock
crictl config image-endpoint unix:///run/containerd/containerd.sock
systemctl restart containerd
systemctl restart kubelet
#分别在node1 和node2 上执行 加入 集群
kubeadm join 192.168.1.3:6443 --token 0dsy6g.zd0uoselslw8trsz \
--discovery-token-ca-cert-hash sha256:52682768ae891700eec9a8466b03b567c832eae753e800c9cceccea7e60396b8
# 加入的结果
[preflight] Running pre-flight checks
[WARNING SystemVerification]: missing optional cgroups: blkio
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
# 上面加入集群的 token 默认有效期为24小时,过期后获取命令
[root@master ~]# kubeadm token create --print-join-command
kubeadm join 192.168.1.11:6443 --token vyywal.v43db43lc7nyp8m3 --discovery-token-ca-cert-hash sha256:43cea477dafece56be8659d18d98ba97bd658d0c3f1987fa66b6861486ed1323
# 根据据提示:在master节点上运行
kubectl get nodes
NAME STATUS ROLES AGE VERSION
master NotReady control-plane 5m10s v1.25.3
node1 NotReady <none> 3m33s v1.25.3
node2 NotReady <none> 3m37s v1.25.3
# 全部处于notready状态
# 还需要在master上安装cni网络插件
# 有着三种 antrea flannel.yml calico
# 此处选择 flannel
# 下面有提供 flannel.yml文件,需要将文件复制进虚拟机,此路径可以任一放
mkdir -p /opt/k8s && cd /opt/k8s
#注意:需要把文件复制进虚拟机后才能运行这一条命令
kubectl apply -f kube-flannel.yml
#下面是calico.yml。但是笔者一直没弄好,更换上面的 flannel.yml ,不需要执行下面的calico.yaml
wget https://docs.projectcalico.org/v3.8/manifests/calico.yaml
sed -i 's/192.168.0.0\/16/10.244.0.0\/16/g' calico.yaml
kubectl apply -f calico.yaml
# 在所有机器上执行
systemctl restart kubelet
systemctl restart containerd
# 在master中查看
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready control-plane 85m v1.25.3
node1 Ready <none> 76m v1.25.3
node2 Ready <none> 76m v1.25.3
# 可以看到节点已经加入成功
以下这代码块是在centos9中运行出现的问题和错误,根据博客等笔者做了一天之后没找到解决办法,则换成了centos7, 这代码块仅仅做记录,当扩大知识面而已。不需要执行
# 出现问题
Get "https://192.168.1.11:6443/api/v1/nodes?limit=500": dial tcp 192.168.1.11:6443: connect: connection refused - error from a previous attempt: http2: server sent GOAWAY and closed the connection; LastStreamID=53, ErrCode=NO_ERROR, debug=""
# 根据这个博客,
#https://blog.csdn.net/qq_29274865/article/details/116016449
# 将/etc/docker/daemon.json 更改如下
[root@master ~]# cat /etc/docker/daemon.json
{
"registry-mirrors": ["https://82m9ar63.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
# 执行之后还是不行,把dokcer命令更改为 crictl
# 发现果然这个跟docker的还是有点区别
crictl info | grep Cgroup
"ShimCgroup": "",
"SystemdCgroup": false
"systemdCgroup": false,
"disableCgroup": false,
https://blog.csdn.net/bbwangj/article/details/82024485
192 systemctl start firewalld
193 systemctl enable firewalld.service
194 firewall-cmd --zone=public --add-port=80/tcp --permanent
195 firewall-cmd --zone=public --add-port=6443/tcp --permanent
196 firewall-cmd --zone=public --add-port=2379-2380/tcp --permanent
197 firewall-cmd --zone=public --add-port=10250-10255/tcp --permanent
198 firewall-cmd --zone=public --add-port=30000-32767/tcp --permanent
199 firewall-cmd --reload
The connection to the server localhost:8080 was refused - did you specify the right host or port?
#kubectl命令需要使用kubernetes-admin来运行
将主节点(master节点)中的【/etc/kubernetes/admin.conf】文件拷贝到从节点相同目录下:
scp -r /etc/kubernetes/admin.conf node1:/etc/kubernetes/admin.conf
scp -r /etc/kubernetes/admin.conf node2:/etc/kubernetes/admin.conf
配置环境变量:
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
systemctl restart containerd
systemctl restart kubelet
需要删除/var/lib/calico这个目录和/etc/cni/net.d/这个目录下的calico文件就行了
整理一下
# 在master,node1,node2 中执行
containerd config default > /etc/containerd/config.toml
crictl config runtime-endpoint unix:///run/containerd/containerd.sock
crictl config image-endpoint unix:///run/containerd/containerd.sock
systemctl restart containerd
crictl pull registry.aliyuncs.com/google_containers/pause:3.6
ctr -n k8s.io i tag registry.aliyuncs.com/google_containers/pause:3.6 registry.k8s.io/pause:3.6
systemctl restart containerd
systemctl restart kubelet
# master上执行
#查看要下载的镜像
kubeadm config images list
registry.k8s.io/kube-apiserver:v1.25.3
registry.k8s.io/kube-controller-manager:v1.25.3
registry.k8s.io/kube-scheduler:v1.25.3
registry.k8s.io/kube-proxy:v1.25.3
registry.k8s.io/pause:3.8
registry.k8s.io/etcd:3.5.4-0
registry.k8s.io/coredns/coredns:v1.9.3
# 下载镜像--阿里镜像 ,coredns 路径有点区别
crictl pull registry.aliyuncs.com/google_containers/kube-apiserver:v1.25.3
crictl pull registry.aliyuncs.com/google_containers/kube-controller-manager:v1.25.3
crictl pull registry.aliyuncs.com/google_containers/kube-scheduler:v1.25.3
crictl pull registry.aliyuncs.com/google_containers/kube-proxy:v1.25.3
crictl pull registry.aliyuncs.com/google_containers/pause:3.8
crictl pull registry.aliyuncs.com/google_containers/etcd:3.5.4-0
crictl pull registry.aliyuncs.com/google_containers/coredns:v1.9.3
# 更换名字
ctr -n k8s.io i tag registry.aliyuncs.com/google_containers/kube-apiserver:v1.25.3 registry.k8s.io/kube-apiserver:v1.25.3
ctr -n k8s.io i tag registry.aliyuncs.com/google_containers/kube-controller-manager:v1.25.3 registry.k8s.io/kube-controller-manager:v1.25.3
ctr -n k8s.io i tag registry.aliyuncs.com/google_containers/kube-scheduler:v1.25.3 registry.k8s.io/kube-scheduler:v1.25.3
ctr -n k8s.io i tag registry.aliyuncs.com/google_containers/kube-proxy:v1.25.3 registry.k8s.io/kube-proxy:v1.25.3
ctr -n k8s.io i tag registry.aliyuncs.com/google_containers/pause:3.8 registry.k8s.io/pause:3.8
ctr -n k8s.io i tag registry.aliyuncs.com/google_containers/etcd:3.5.4-0 registry.k8s.io/etcd:3.5.4-0
ctr -n k8s.io i tag registry.aliyuncs.com/google_containers/coredns:v1.9.3 registry.k8s.io/coredns/coredns:v1.9.3
kubeadm init \
--apiserver-advertise-address=192.168.1.3 \
--image-repository registry.aliyuncs.com/google_containers \
--service-cidr=10.1.0.0/16 \
--kubernetes-version v1.25.3 \
--pod-network-cidr=10.244.0.0/16
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
# 在node1 node2 执行
kubeadm join 192.168.1.3:6443 --token xrdrx2.84gxr8294kk9kfyj \
--discovery-token-ca-cert-hash sha256:53d570d5017b6eb085e82eb3904e6977b450aed73de76773f7778b18c06ca038
# 下面有提供 flannel.yml文件,需要将文件复制进虚拟机,此路径可以任一放
mkdir -p /opt/k8s && cd /opt/k8s
#注意:需要把文件复制进虚拟机后才能运行这一条命令
kubectl apply -f kube-flannel.yml
#在所有机器上执行
systemctl restart containerd
systemctl restart kubelet
#稍等一会儿 1分钟左右
kubectl get nodes
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready control-plane 2m46s v1.25.3
node1 Ready <none> 82s v1.25.3
node2 Ready <none> 76s v1.25.3
flannel.yml
---
kind: Namespace
apiVersion: v1
metadata:
name: kube-flannel
labels:
pod-security.kubernetes.io/enforce: privileged
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: flannel
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- ""
resources:
- nodes
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: flannel
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: flannel
subjects:
- kind: ServiceAccount
name: flannel
namespace: kube-flannel
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: flannel
namespace: kube-flannel
---
kind: ConfigMap
apiVersion: v1
metadata:
name: kube-flannel-cfg
namespace: kube-flannel
labels:
tier: node
app: flannel
data:
cni-conf.json: |
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: kube-flannel-ds
namespace: kube-flannel
labels:
tier: node
app: flannel
spec:
selector:
matchLabels:
app: flannel
template:
metadata:
labels:
tier: node
app: flannel
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
hostNetwork: true
priorityClassName: system-node-critical
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni-plugin
#image: flannelcni/flannel-cni-plugin:v1.1.0 for ppc64le and mips64le (dockerhub limitations may apply)
image: docker.io/rancher/mirrored-flannelcni-flannel-cni-plugin:v1.1.0
command:
- cp
args:
- -f
- /flannel
- /opt/cni/bin/flannel
volumeMounts:
- name: cni-plugin
mountPath: /opt/cni/bin
- name: install-cni
#image: flannelcni/flannel:v0.20.1 for ppc64le and mips64le (dockerhub limitations may apply)
image: docker.io/rancher/mirrored-flannelcni-flannel:v0.20.1
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
#image: flannelcni/flannel:v0.20.1 for ppc64le and mips64le (dockerhub limitations may apply)
image: docker.io/rancher/mirrored-flannelcni-flannel:v0.20.1
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
limits:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: false
capabilities:
add: ["NET_ADMIN", "NET_RAW"]
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: EVENT_QUEUE_DEPTH
value: "5000"
volumeMounts:
- name: run
mountPath: /run/flannel
- name: flannel-cfg
mountPath: /etc/kube-flannel/
- name: xtables-lock
mountPath: /run/xtables.lock
volumes:
- name: run
hostPath:
path: /run/flannel
- name: cni-plugin
hostPath:
path: /opt/cni/bin
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg
- name: xtables-lock
hostPath:
path: /run/xtables.lock
type: FileOrCreate
测试
#在master查看网络情况,如果是用calico ,这里就不是running 老是containcreating 。百度无果后换成flannel
[root@master ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-c676cc86f-dqpcz 1/1 Running 0 28m
coredns-c676cc86f-dswkc 1/1 Running 0 28m
etcd-master 1/1 Running 0 28m
kube-apiserver-master 1/1 Running 0 28m
kube-controller-manager-master 1/1 Running 0 28m
kube-proxy-dt7w4 1/1 Running 0 26m
kube-proxy-hr449 1/1 Running 0 26m
kube-proxy-tjqfk 1/1 Running 0 28m
kube-scheduler-master 1/1 Running 0 28m
# 创建pod ,测试 pod
[root@master ~]# kubectl create deployment nginx --image=nginx
deployment.apps/nginx created
[root@master ~]# kubectl expose deployment nginx --port=80 --type=NodePort
service/nginx exposed
# 此处需要等大概1分钟左右,笔者的网络是千兆网络
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-76d6c9b8c-cwsfn 0/1 ContainerCreating 0 2m41s
# 1分钟后就变成running
[root@master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-76d6c9b8c-mftnr 1/1 Running 0 84s
[root@master k8s]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.1.0.1 <none> 443/TCP 33m
nginx NodePort 10.1.124.77 <none> 80:32542/TCP 3m7s
# 注意nginx的port ,此处 80 映射到了 32542
# 在宿主主机上web上访问 192.168.1.32542 ,可以成功访问nginx首页

下面代码块也是小插曲,本来使用calcio 的网络插件,下面是一些错误和解决方案,但是这些解决方案都是无效的,最后calcio 插件换成了flannel
# 查看pod日志
kubectl describe pods -n kube-system coredns-5bfd685c78-mmjxc
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 154m default-scheduler 0/1 nodes are available: 1 node(s) had untolerated taint {node.kubernetes.io/not-ready: }. preemption: 0/1 nodes are available: 1 Preemption is not helpful for scheduling.
Normal Scheduled 152m default-scheduler Successfully assigned kube-system/coredns-c676cc86f-5xbpk to master
Warning FailedCreatePodSandBox 152m kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "f5e94bf8c9bc61aa3c1d1ba424d9f8cc8dea0f35df11d8e5024d7eb14a5264d6": plugin type="calico" failed (add): stat /var/lib/calico/nodename: no such file or directory: check that the calico/node container is running and has mounted /var/lib/calico/
Normal SandboxChanged 122m (x139 over 152m) kubelet Pod sandbox changed, it will be killed and re-created.
Warning FailedCreatePodSandBox 3m41s kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "30bcb3b2a5ac63826088fd3c4b846044188e4b992c3bb0429ec4be58eb685732": plugin type="calico" failed (add): stat /var/lib/calico/nodename: no such file or directory: check that the calico/node container is running and has mounted /var/lib/calico/
Normal SandboxChanged 11s (x17 over 3m42s) kubelet Pod sandbox changed, it will be killed and re-created.
rm -rf /etc/cni/net.d/*
rm -rf /var/lib/cni/calico
systemctl restart kubelet
ssh-keygen -t rsa
ssh-copy-id root@node1
ssh-copy-id root@node2
scp -r /etc/kubernetes/pki/etcd root@node1:/etc/kubernetes/pki/etcd
scp -r /etc/kubernetes/pki/etcd root@node2:/etc/kubernetes/pki/etcd
Warning Unhealthy 6m9s (x2 over 6m9s) kubelet Readiness probe errored: rpc error: code = NotFound desc = failed to exec in container: failed to load task: no running task found: task 2a0bf33fb9f4ad712b396b3f3f3e8114846c424b19e069c503882f2b14705594 not found: not found
Container image "calico/node:v3.8.9" already present on machine
Warning BackOff 4m45s (x12 over 6m7s) kubelet Back-off restarting failed container
Warning Unhealthy 8m36s kubelet Readiness probe errored: rpc error: code = NotFound desc = failed to exec in container: failed to load task: no running task found: task e81350b8a7bfd0be631a01f236b4b9f86df1344428f6de48b3babd5c00f1b347 not found: not found
Warning Unhealthy 8m36s (x2 over 8m36s) kubelet Readiness probe errored: rpc error: code = Unknown desc = failed to exec in container: container is in CONTAINER_EXITED state
Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "9b8e8e80829485152f625177a8bde9b594145d75ced0ead908a24a10528b93af": plugin type="calico" failed (add): stat /var/lib/calico/nodename: no such file or directory: check that the calico/node container is running and has mounted /var/lib/calico/
可以通过如下方法解决: #创建目录和文件 mkdir /var/lib/calico/ touch /var/lib/calico/nodename #将本机ip写进nodename文件中
echo "192.168.1.3" > /var/lib/calico/nodename
命令行工具kubectl
是k8s集群的命令行工具
kubectl 命令语法
kubectl [command] [type] [name] [flags]
command : 指定要对资源执行的操作,如:create,get,describe 和delete
type: 指定资源类型,大小写敏感,但是单数、复数、缩略的形式呈现
kubectl get pod podname kubectl get pods podname kubectl get po podname- name 指定资源类型的名称,名称也是大小写敏感的。
- flags 指定可选的参数,如 -s 或者 -server 指定kubenets API Server的地址和端口号
kubectl 子命令使用分类
基础命令
create 通过文件名或者标准输入创建资源 expose 将一个资源公开为一个新的service run 在集群中运行一个特定的镜像 set 在对象上设置特定的功能 explain 文档参考资源,元信息 edit 使用默认的没编辑器编辑一个资源 delete 通过文件名,标准输入,资源名或标签选择器来删除资源 部署命令
| rollout | 管理资源的发布 |
|---|---|
| rolling-update | 对给顶的赋值控制器滚动更新 |
| scale | 扩容或缩容pod数量 |
| autoscale | 创建一个自动选择扩容或缩容并设置pod数量 |
集群管理命令
| certificate | 修改证书资源 |
|---|---|
| cluster-info | 显示集群信息 |
| top | 显示资源使用,需要heapster运行 |
| cordon | 表记节点不可调度 |
| uncordon | 标记节点调度 |
| drain | 去车主节点上的应用,准备下线维护 |
| taint | 修改节点taint标记 |
故障调试命令
| describe | 显示特定资源或资源组的详细信息 |
|---|---|
| logs | 在一个pod中打印一个容器日志, |
| attach | 附加到一个运行的容器,类似于docker的attach |
| exec | 执行命令到容器 |
| port-forward | 转发一个或多个本地端口到一个pod |
| proxy | 运行一个proxy到k8s api server |
| cp | 拷贝文件或目录到容器中 |
| auth | 检查授权 |
其他命令
| apply | 通过文件名或标准输入对资源应用配置 |
|---|---|
| patch | 使用补丁修改、更新资源的字段 |
| replace | 通过文件名或标准输入替换一个资源 |
| convert | 不同的API版本之间转换配置工具 |
| label | 更新资源上的标签 |
| annotate | 更新资源上的注释 |
| completion | 用于实现kubectl工具自动补全 |
| api-versions | 打印受支持的API版本 |
| config | 修改kubeconfig文件,用于访问API,比如配置认证信息 |
| help | 所有命令帮助 |
| plugin | 运行一个命令行插件 |
| version | 打印客户端和服务版本信息 |
Yaml
- 使用空格作为缩进,低版本不允许用Tab键
- 缩进的空格数目不重要,只要相同层级的元素左侧对其即可
- 使用 --- 表示新的文件
- 组成部分
- template 之前: 定义控制器
- template 之后包括template : 被控制对象
kubectl --help
Other Commands:
alpha Commands for features in alpha
api-resources Print the supported API resources on the server # 查看所有资源
api-versions Print the supported API versions on the server, in the form of "group/version" # 查看所有版本
config 修改 kubeconfig 文件
plugin Provides utilities for interacting with plugins
version 输出 client 和 server 的版本信息
- 常见说明
| apiVersion | API版本 |
|---|---|
| kind | 资源类型 |
| metadata | 资源元数据 |
| spec | 资源规格 |
| replicas | 副本数量 |
| selector | 标签选择器 |
| template | Pod模板 |
| metadata | Pod元数据 |
| spec | Pod规格 |
| container | 容器配置 |
资源清单描述方法
使用YAM格式的文件来创建符合与其期望的Pod文件,这样的yaml文件称为资源清单
常用字段
必须存在的字段
| 参数名 | 字段类型 | 说明 |
|---|---|---|
| version | String | 目前基本是v1,可以用kubectl api-versions 命令查询 |
| king | String | yaml文件定义的自选类型和角色,比如Pod |
| metadata | Object | 元数据对象 |
| metadata.name | String | 元数据对象的名字,可自定义 |
| metadata.namespace | String | 元数据对象的命名空间,可自定义,查找命令加上 -n |
| Spec | Object | 详细定义对象 |
| Spec.container[] | list | 这里是Spec对象的容器列表定义 |
| Spec.container[].name | String | 定义容器的名字 |
| Spec.container[].image | String | 定义要用到的镜像名称 |
| Spec.container[].imagePullPolicy | String | 镜像拉取策略 1. Always: 每次尝试重新拉取新的镜像(默认值) 2.Never: 仅仅使用本地镜像 3.ifNotPresent: 如果本地有镜像就用本地镜像,没有就拉取在线镜像 |
| Spec.container[].command[] | list | 指定容器启动命令,因为是数组可以指定多个,不指定则使用镜像打包时使用的启动命令 |
| Spec.container[].args[] | list | 指定容器启动命令参数 |
| Spec.container[].workingDir | String | 指定容器的工作目录 |
| Spec.container[].volumeMounts[] | list | 指定容器内部的存储卷配置 |
| Spec.container[].volumeMounts[].name | String | 指定可以被容器挂载的存储卷的名称 |
| Spec.container[].volumeMounts[].mountPath | String | 指定可以被容器挂载的容器卷的路径 |
| Spec.container[].volumeMounts[].readOnly | Boolean | 是不只读 |
| Spec.container[].ports[] | List | 指定容器需要用到的端口列表 |
| Spec.container[].ports[].name | String | 端口名称 |
| Spec.container[].ports[].containerPort | String | 指定容器需要监听的端口号 |
| Spec.container[].ports[].hostPort | Strign | 指定容器所在主机需要监听的端口号,默认跟上面商贸通,注意设置了hostPort同一台主机无法启动该容器的相同副本,因为主机的端口号不能相同,这样会冲突 |
| Spec.container[].ports[].protocol | String | 指定端口协议,支持TCP和UDP,默认值为TCP |
| Spec.container[].env[] | list | 指定容器运行设置的环境变量列表 |
| Spec.container[].env[].name | String | 指定环境变量名称 |
| Spec.container[].env[].value | String | 指定环境变量值 |
| Spec.container[].resources | Objects | 指定资源限制和资源请求的值 |
| Spec.container[].resources.limits | Ojbects | 容器运行时资源的运行上限 |
| Spec.container[].resources.limits.cpu | String | 指定CPU的限制,单位为core数,将用于 docker run --cpu-shares 参数 |
| Spec.container[].resources.limits.memory | String | 指定mem内存的限制,单位为MIB,GIB |
| Spec.container[].resources.requests | Object | 指定容器启动和调度室的限制设置 |
| Spec.container[].resources.requests.cpu | String | CPU请求,单位为core数,容器启动时初始化可用数量 |
| Spec.container[].resources.request.memory | String | 内存请求,单位为MIB,GIB容器启动的初始化可用数量 |
额外的参数
| spec.restartPolicy | String | 定义Pod重启策略,默认值Always 1. always: pod一旦终止运行,则无论容器时如何终止的,kubelet服务都将重启它 2.OnFailure: 只有Pod以非零退出码终止时,kubelet才会重启该容器.如果容器正常结束(退出码为0),则kubelet将不会重启它 3.Never:pod终止后,kubelet将退出码报告给master,不会重启该pod |
|---|---|---|
| spec.nodeSelector | Object | 定义node的Label过滤标签,以key:value格式指定 |
| spec.imagePulSecrets | Object | 定义pull镜像使用secret名称,以name:secretkey指定格式 |
| spec.hostNetWork | Boolean | 定义是否使用主机网络模式,默认为false,设置true表示使用宿主主机网络,不实用docker网桥,同时设置了true将无法再同一台宿主主机上启动第二个副本 |
快速编写yaml文件
- 使用kubectl create 命令生成yaml文件
- 使用kubectl get命令查看yaml文件,需要导入 可以 > my.yaml 进行输出的my.yaml文件中
[root@k8s-node1 test]# kubectl create deployment web --image=nginx -o yaml --dry-run
W1216 17:12:18.604484 23514 helpers.go:598] --dry-run is deprecated and can be replaced with --dry-run=client.
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: web
name: web
spec:
replicas: 1
selector:
matchLabels:
app: web
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
resources: {}
status: {}
[root@k8s-node1 test]# ls
[root@k8s-node1 test]# ls
[root@k8s-node1 test]# ll
总用量 0
[root@k8s-node1 test]#
[root@k8s-master ~]# kubectl get deploy web-test -o yaml
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
creationTimestamp: "2022-12-16T09:19:27Z"
generation: 1
labels:
app: web-test
name: web-test
namespace: default
resourceVersion: "2818987"
uid: 1e2624d1-355e-4bcc-bf33-8b606895514f
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: web-test
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: web-test
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: nginx
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
status:
availableReplicas: 1
conditions:
- lastTransitionTime: "2022-12-16T09:19:51Z"
lastUpdateTime: "2022-12-16T09:19:51Z"
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
- lastTransitionTime: "2022-12-16T09:19:27Z"
lastUpdateTime: "2022-12-16T09:19:51Z"
message: ReplicaSet "web-test-64c6575bd7" has successfully progressed.
reason: NewReplicaSetAvailable
status: "True"
type: Progressing
observedGeneration: 1
readyReplicas: 1
replicas: 1
updatedReplicas: 1
Pod
概念
- Pod是k8s系统中可以创建和管理的最小单元(不是容器),是资源对象模型中由用户创建或部署的最小资源对象模型
- 一个或多个容器组成
- k8s不会处理容器,而是处理pod
- 一个pod中容器共享网络命名空间
- 每一个Pod 都有一个特殊的被称为"根容器"的Pause容器
- 每个Pod包含一个或多个业务容器
- Pod是短暂的
- 同一个Pod 中的容器总会被调度到相同Node 节点,不同节点间Pod 的通信基于虚拟二层网络技术实现
存在的意义
- 一个docker容器只能有一个应用程序
- 一次运行只能运行一个容器
实现机制
共享网络
利用linux的namespace ,cgroup 通过Pause 容器,把其他业务容器加入到Pause容器李面,让所有业务容器在同一个名称空间中,实现网络共享
共享存储
利用数据卷的概念实现共享存储
镜像拉取策略
- Always: 每次尝试重新拉取新的镜像(默认值)
- 2.Never: 仅仅使用本地镜像
- ifNotPresent: 如果本地有镜像就用本地镜像,没有就拉取在线镜像
Pod健康检查
应用层面健康检测,而不是Pod本身的健康检测
spec:
containers:
- name: liveness
image: busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe 存活检查
如果检查失败,将杀死容器,根据Pod的restartPolicy来操作
readinessProbe 就绪检查
如果检查失败,k8s会把Pod从Service endpoints中剔除
Probe支持以下三种检查方法
- httpget 发送HTTP请求,返回200-400范围状态码均为成功
- exec 执行shell命令返回状态码是0为成功
- tcpSocket 发起TCP Socket 建立成功
Pod调度策略-创建Pod
kubectl crate -f xxx.yaml
# 查看
kubectl get pod/po <Pod_name>
kubectl get pod/po <Pod_name> -o wide
kubectl describe pod/po <pod_name>
# 删除
kubectl delete -f pod pod_name.yaml
kubectl delete pod --all/<pod_name>
静态pod和普通pod
- 普通pod
普通Pod 一旦被创建,就会被放入到etcd 中存储,随后会被Kubernetes Master 调度到某具体的Node 上并进行绑定,随后该Pod 对应的Node 上的kubelet 进程实例化成一组相关的Docker 容器并启动起来。在默认情况下,当Pod 里某个容器停止时,Kubernetes 会自动检测到这个问题并且重新启动这个Pod 里某所有容器, 如果Pod 所在的Node 宕机,则会将这个Node 上的所有Pod 重调度到其它节点上。
- 静态pod
静态Pod 是由kubelet 进行管理的仅存在于特定Node 上的Pod,它们不能通过API Server进行管理,无法与ReplicationController、Deployment 或DaemonSet 进行关联,并且kubelet 也无法对它们进行健康检查。
有状态和无状态
- 无状态:
- 没有顺序要求
- 不用考虑在哪个node上运行
- 随意进行伸缩和扩展
- 有状态
- 每个pod是独立的,保持pod启动的顺序性和唯一性
- 唯一的网络标识符,持久存储
- 启动有序,比如mysql主从
影响Pod调度-资源限制和节点选择器
节点先满足yaml中设置的资源限制
限制Pod是在dev的节点上运行
spec:
nodeSelector:
env_role: dev
- 如何给节点起标签
kubectl label node 节点名称 key=value
kubectl label node node1 env_role=dev
影响Pod调度-节点亲和性
节点亲和性 nodeAffinity 比 nodeSelector功能更加强大
硬亲和性 约束条件必须满足
软亲和性 约束条件如果有就满足,如果没有也可以运行
spec:
affinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: env_role
oprator: In
values:
- dev
- test
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: group
operator: In
values:
- otherprod
- 上图中硬亲和性:表示必须在dev或者test中运行
- 上图中软亲和性:表示可以在otherpod环境中尝试满足.
operator:In
表示操作符,表示 key env_role 中的value 在 dev 或者在test
常见操作符
In
NotIn
Exists
Gt
Lt
DoesNotExists
影响Pod调度-污点和污点容忍
nodeSelector 和 nodeAffinity: Pod调度到某些节点上,Pod属性,调度时候实现 Taint 污点,节点不做普通分配调度,是节点属性
场景:
- 专用节点
- 配置特点硬件特点
- 基于Taint驱逐
查看节点污点情况
kubectl describe node nodeName |grep Taint
污点值得选额
- NoSchedule: 一定不被调度 (Node被添加上该值,新增的Pod不会调度该node上)
- PreferNoSchedule: 尽量不被调度
- NoExecute: 不会调度,并且会驱逐Node已有Pod
为节点添加污点值
kubectl taint node [nodeName] key=value:NoSchedule
取消污点值
kubectl taint node [nodeName] key=value:NoSchedule-
快速扩展deployment的web的副本
kubectl scale deployment web --replicas=5
Controller-Deployment-无状态应用
deployment是常见的controller的一种
什么是Controller
在集群上管理和运行容器的对象
Pod和Controller关系
pod是通过controller 实现应用的运维,比如伸缩,滚动升级等等
pod和controller之间通过label标签建立
Deployment控制器应用场景
- 部署无状态应用
- 管理pod和replicaset
- 部署,滚动升级等功能
- 应用场景:web服务,微服务
Deployment控制器部署应用
升级回滚
弹性伸缩
发布应用
获取yaml
kubectl create deployment web --image=nginx -o yaml --dry-run=client > web.yaml
部署
kubectl apply -f web.yaml
暴露端口
kubectl expose --help
# 命令暴露
kubectl expose deployment web --port=80(内部端口) --type=NodePort --target-port=80(外部访问端口) --name=web1
# yaml暴露
kubectl expose deployment web --port=80(内部端口) --type=NodePort --target-port=80(外部访问端口) --name=web1 -o yaml > web1.yaml
kubectl apply -f web1.yaml
升级回滚
kubectl set image deployement web nginx=nginx:1.15
kubectl rollout status deployment web
# 查看升级历史
kubectl rollout history deployment web
# 回滚上一个版本
kubectl rollout undo deployment web
#回滚指定版本
kubectl rollout undo deployment web --to-revision=2
弹性伸缩
快速扩展deployment的web的副本
kubectl scale deployment web --replicas=5
Service
定义一组pod的访问规则(负载均衡)
防止pod失联
通过label和selector建立关联
服务A 有3个Pod
服务B也有 3 个pod
Service充当 服务A 和服务B 之间的服务发现
三种类型
- clusterIp 集群内部使用
- nodeport 对外访问(暴露)使用
- loadblance : 对外访问应用使用,公有云
Controller-StatefulSate-有状态应用
部署有状态应用
headless Service
即
kubectl get svc中的网络ip为nullspec.clusterIp:none
Controller-DaemonSet-守护进程
- 在每个node上运行一个pod,新加入的node也会自动运行一个新的pod
kind中定义为DaemonSet
进入pod内部
kubectl exec -it podname bash
查看日志
/var/log/pods